

14. Bidirectional GRU seq2seq
import sys
import warnings
if not sys.warnoptions:
warnings.simplefilter('ignore')
In [2]:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from datetime import datetime
from datetime import timedelta
from tqdm import tqdm
sns.set()
tf.compat.v1.random.set_random_seed(1234)
In [3]:
df = pd.read_csv('../dataset/GOOG-year.csv')
df.head()
Out[3]:
| Date | Open | High | Low | Close | Adj Close | Volume | |
| 0 | 2016-11-02 | 778.200012 | 781.650024 | 763.450012 | 768.700012 | 768.700012 | 1872400 |
| 1 | 2016-11-03 | 767.250000 | 769.950012 | 759.030029 | 762.130005 | 762.130005 | 1943200 |
| 2 | 2016-11-04 | 750.659973 | 770.359985 | 750.560974 | 762.020020 | 762.020020 | 2134800 |
| 3 | 2016-11-07 | 774.500000 | 785.190002 | 772.549988 | 782.520020 | 782.520020 | 1585100 |
| 4 | 2016-11-08 | 783.400024 | 795.632996 | 780.190002 | 790.510010 | 790.510010 | 1350800 |
In [4]:
minmax = MinMaxScaler().fit(df.iloc[:, 4:5].astype('float32')) # Close index
df_log = minmax.transform(df.iloc[:, 4:5].astype('float32')) # Close index
df_log = pd.DataFrame(df_log)
df_log.head()
Out[4]:
| 0 | |
| 0 | 0.112708 |
| 1 | 0.090008 |
| 2 | 0.089628 |
| 3 | 0.160459 |
| 4 | 0.188066 |
Split train and test
I will cut the dataset to train and test the datasets,
Training dataset derived from the start timestamp until the last 30 days
Test dataset derived from the last 30 days until the end of the dataset
So we will let the model do forecasting based on the last 30 days, and we will going to repeat the experiment 10 times. You can increase it locally if you want, and tuning parameters will help you a lot.
In [5]:
test_size = 30
simulation_size = 10
df_train = df_log.iloc[:-test_size]
df_test = df_log.iloc[-test_size:]
df.shape, df_train.shape, df_test.shape
Out[5]:
((252, 7), (222, 1), (30, 1))
In [6]:
class Model:
def __init__(
self,
learning_rate,
num_layers,
size,
size_layer,
output_size,
forget_bias = 0.1,
):
def lstm_cell(size_layer):
return tf.nn.rnn_cell.GRUCell(size_layer)
backward_rnn_cells = tf.nn.rnn_cell.MultiRNNCell(
[lstm_cell(size_layer) for _ in range(num_layers)],
state_is_tuple = False,
)
forward_rnn_cells = tf.nn.rnn_cell.MultiRNNCell(
[lstm_cell(size_layer) for _ in range(num_layers)],
state_is_tuple = False,
)
self.X = tf.placeholder(tf.float32, (None, None, size))
self.Y = tf.placeholder(tf.float32, (None, output_size))
drop_backward = tf.contrib.rnn.DropoutWrapper(
backward_rnn_cells, output_keep_prob = forget_bias
)
forward_backward = tf.contrib.rnn.DropoutWrapper(
forward_rnn_cells, output_keep_prob = forget_bias
)
self.backward_hidden_layer = tf.placeholder(
tf.float32, shape = (None, num_layers * size_layer)
)
self.forward_hidden_layer = tf.placeholder(
tf.float32, shape = (None, num_layers * size_layer)
)
_, last_state = tf.nn.bidirectional_dynamic_rnn(
forward_backward,
drop_backward,
self.X,
initial_state_fw = self.forward_hidden_layer,
initial_state_bw = self.backward_hidden_layer,
dtype = tf.float32,
)
with tf.variable_scope('decoder', reuse = False):
backward_rnn_cells_decoder = tf.nn.rnn_cell.MultiRNNCell(
[lstm_cell(size_layer) for _ in range(num_layers)],
state_is_tuple = False,
)
forward_rnn_cells_decoder = tf.nn.rnn_cell.MultiRNNCell(
[lstm_cell(size_layer) for _ in range(num_layers)],
state_is_tuple = False,
)
drop_backward_decoder = tf.contrib.rnn.DropoutWrapper(
backward_rnn_cells_decoder, output_keep_prob = forget_bias
)
forward_backward_decoder = tf.contrib.rnn.DropoutWrapper(
forward_rnn_cells_decoder, output_keep_prob = forget_bias
)
self.outputs, self.last_state = tf.nn.bidirectional_dynamic_rnn(
forward_backward_decoder, drop_backward_decoder, self.X,
initial_state_fw = last_state[0],
initial_state_bw = last_state[1],
dtype = tf.float32
)
self.outputs = tf.concat(self.outputs, 2)
self.logits = tf.layers.dense(self.outputs[-1], output_size)
self.cost = tf.reduce_mean(tf.square(self.Y - self.logits))
self.optimizer = tf.train.AdamOptimizer(learning_rate).minimize(
self.cost
)
def calculate_accuracy(real, predict):
real = np.array(real) + 1
predict = np.array(predict) + 1
percentage = 1 - np.sqrt(np.mean(np.square((real - predict) / real)))
return percentage * 100
def anchor(signal, weight):
buffer = []
last = signal[0]
for i in signal:
smoothed_val = last * weight + (1 - weight) * i
buffer.append(smoothed_val)
last = smoothed_val
return buffer
In [7]:
num_layers = 1
size_layer = 128
timestamp = 5
epoch = 300
dropout_rate = 0.8
future_day = test_size
learning_rate = 0.01
In [8]:
def forecast():
tf.reset_default_graph()
modelnn = Model(
learning_rate, num_layers, df_log.shape[1], size_layer, df_log.shape[1], dropout_rate
)
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
date_ori = pd.to_datetime(df.iloc[:, 0]).tolist()
pbar = tqdm(range(epoch), desc = 'train loop')
for i in pbar:
init_value_forward = np.zeros((1, num_layers * size_layer))
init_value_backward = np.zeros((1, num_layers * size_layer))
total_loss, total_acc = [], []
for k in range(0, df_train.shape[0] - 1, timestamp):
index = min(k + timestamp, df_train.shape[0] - 1)
batch_x = np.expand_dims(
df_train.iloc[k : index, :].values, axis = 0
)
batch_y = df_train.iloc[k + 1 : index + 1, :].values
logits, last_state, _, loss = sess.run(
[modelnn.logits, modelnn.last_state, modelnn.optimizer, modelnn.cost],
feed_dict = {
modelnn.X: batch_x,
modelnn.Y: batch_y,
modelnn.backward_hidden_layer: init_value_backward,
modelnn.forward_hidden_layer: init_value_forward,
},
)
init_value_forward = last_state[0]
init_value_backward = last_state[1]
total_loss.append(loss)
total_acc.append(calculate_accuracy(batch_y[:, 0], logits[:, 0]))
pbar.set_postfix(cost = np.mean(total_loss), acc = np.mean(total_acc))
future_day = test_size
output_predict = np.zeros((df_train.shape[0] + future_day, df_train.shape[1]))
output_predict[0] = df_train.iloc[0]
upper_b = (df_train.shape[0] // timestamp) * timestamp
init_value_forward = np.zeros((1, num_layers * size_layer))
init_value_backward = np.zeros((1, num_layers * size_layer))
for k in range(0, (df_train.shape[0] // timestamp) * timestamp, timestamp):
out_logits, last_state = sess.run(
[modelnn.logits, modelnn.last_state],
feed_dict = {
modelnn.X: np.expand_dims(
df_train.iloc[k : k + timestamp], axis = 0
),
modelnn.backward_hidden_layer: init_value_backward,
modelnn.forward_hidden_layer: init_value_forward,
},
)
init_value_forward = last_state[0]
init_value_backward = last_state[1]
output_predict[k + 1 : k + timestamp + 1] = out_logits
if upper_b != df_train.shape[0]:
out_logits, last_state = sess.run(
[modelnn.logits, modelnn.last_state],
feed_dict = {
modelnn.X: np.expand_dims(df_train.iloc[upper_b:], axis = 0),
modelnn.backward_hidden_layer: init_value_backward,
modelnn.forward_hidden_layer: init_value_forward,
},
)
output_predict[upper_b + 1 : df_train.shape[0] + 1] = out_logits
future_day -= 1
date_ori.append(date_ori[-1] + timedelta(days = 1))
init_value_forward = last_state[0]
init_value_backward = last_state[1]
for i in range(future_day):
o = output_predict[-future_day - timestamp + i:-future_day + i]
out_logits, last_state = sess.run(
[modelnn.logits, modelnn.last_state],
feed_dict = {
modelnn.X: np.expand_dims(o, axis = 0),
modelnn.backward_hidden_layer: init_value_backward,
modelnn.forward_hidden_layer: init_value_forward,
},
)
init_value_forward = last_state[0]
init_value_backward = last_state[1]
output_predict[-future_day + i] = out_logits[-1]
date_ori.append(date_ori[-1] + timedelta(days = 1))
output_predict = minmax.inverse_transform(output_predict)
deep_future = anchor(output_predict[:, 0], 0.3)
return deep_future[-test_size:]
In [9]:
results = []
for i in range(simulation_size):
print('simulation %d'%(i + 1))
results.append(forecast())
WARNING: Logging before flag parsing goes to stderr.
W0816 18:33:46.362064 140384958228288 deprecation.py:323] From <ipython-input-6-2500790da2db>:12: GRUCell.__init__ (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.
Instructions for updating:
This class is equivalent as tf.keras.layers.GRUCell, and will be replaced by that in Tensorflow 2.0.
W0816 18:33:46.364130 140384958228288 deprecation.py:323] From <ipython-input-6-2500790da2db>:16: MultiRNNCell.__init__ (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.
Instructions for updating:
This class is equivalent as tf.keras.layers.StackedRNNCells, and will be replaced by that in Tensorflow 2.0.
simulation 1
W0816 18:33:46.687459 140384958228288 lazy_loader.py:50]
The TensorFlow contrib module will not be included in TensorFlow 2.0.
For more information, please see:
* https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
* https://github.com/tensorflow/addons
* https://github.com/tensorflow/io (for I/O related ops)
If you depend on functionality not listed there, please file an issue.
W0816 18:33:46.692470 140384958228288 deprecation.py:323] From <ipython-input-6-2500790da2db>:42: bidirectional_dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.
Instructions for updating:
Please use `keras.layers.Bidirectional(keras.layers.RNN(cell))`, which is equivalent to this API
W0816 18:33:46.693083 140384958228288 deprecation.py:323] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/rnn.py:464: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.
Instructions for updating:
Please use `keras.layers.RNN(cell)`, which is equivalent to this API
W0816 18:33:46.884588 140384958228288 deprecation.py:506] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/init_ops.py:1251: calling VarianceScaling.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
W0816 18:33:46.891244 140384958228288 deprecation.py:506] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/rnn_cell_impl.py:564: calling Constant.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
W0816 18:33:46.900250 140384958228288 deprecation.py:506] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/rnn_cell_impl.py:574: calling Zeros.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
W0816 18:33:47.374557 140384958228288 deprecation.py:323] From <ipython-input-6-2500790da2db>:67: dense (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.dense instead.
train loop: 100%|██████████| 300/300 [02:28<00:00, 2.02it/s, acc=97.7, cost=0.00125]
simulation 2
train loop: 100%|██████████| 300/300 [02:26<00:00, 2.05it/s, acc=98.3, cost=0.000708]
simulation 3
train loop: 100%|██████████| 300/300 [02:29<00:00, 2.01it/s, acc=98.1, cost=0.000848]
simulation 4
train loop: 100%|██████████| 300/300 [02:27<00:00, 2.03it/s, acc=98.5, cost=0.000662]
simulation 5
train loop: 100%|██████████| 300/300 [02:30<00:00, 2.01it/s, acc=97.4, cost=0.0017]
simulation 6
train loop: 100%|██████████| 300/300 [02:29<00:00, 2.01it/s, acc=97.7, cost=0.00127]
simulation 7
train loop: 100%|██████████| 300/300 [02:30<00:00, 1.99it/s, acc=98.3, cost=0.000625]
simulation 8
train loop: 100%|██████████| 300/300 [02:29<00:00, 2.01it/s, acc=98.2, cost=0.000883]
simulation 9
train loop: 100%|██████████| 300/300 [02:29<00:00, 2.01it/s, acc=98.5, cost=0.000547]
simulation 10
train loop: 100%|██████████| 300/300 [02:29<00:00, 2.00it/s, acc=96.9, cost=0.00229]
In [10]:
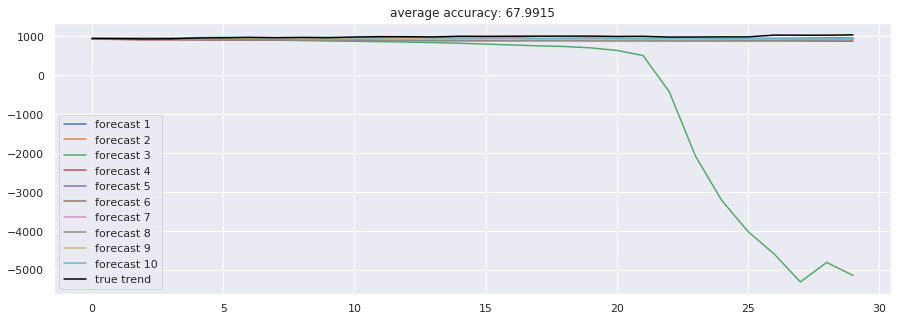
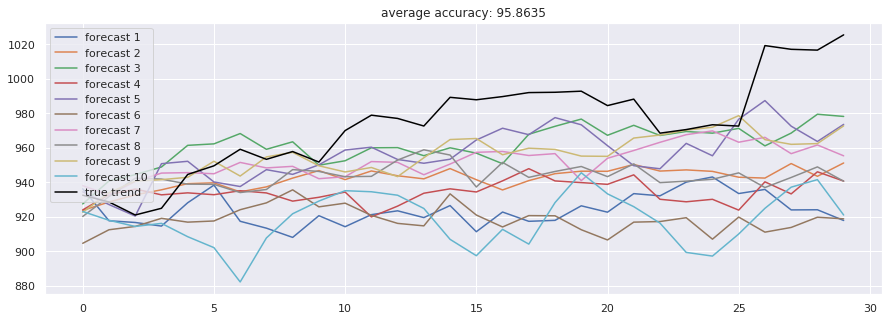
accuracies = [calculate_accuracy(df['Close'].iloc[-test_size:].values, r) for r in results]
plt.figure(figsize = (15, 5))
for no, r in enumerate(results):
plt.plot(r, label = 'forecast %d'%(no + 1))
plt.plot(df['Close'].iloc[-test_size:].values, label = 'true trend', c = 'black')
plt.legend()
plt.title('average accuracy: %.4f'%(np.mean(accuracies)))
plt.show()
15. GRU seq2seq VAE
import sys
import warnings
if not sys.warnoptions:
warnings.simplefilter('ignore')
In [2]:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from datetime import datetime
from datetime import timedelta
from tqdm import tqdm
sns.set()
tf.compat.v1.random.set_random_seed(1234)
In [3]:
df = pd.read_csv('../dataset/GOOG-year.csv')
df.head()
Out[3]:
| Date | Open | High | Low | Close | Adj Close | Volume | |
| 0 | 2016-11-02 | 778.200012 | 781.650024 | 763.450012 | 768.700012 | 768.700012 | 1872400 |
| 1 | 2016-11-03 | 767.250000 | 769.950012 | 759.030029 | 762.130005 | 762.130005 | 1943200 |
| 2 | 2016-11-04 | 750.659973 | 770.359985 | 750.560974 | 762.020020 | 762.020020 | 2134800 |
| 3 | 2016-11-07 | 774.500000 | 785.190002 | 772.549988 | 782.520020 | 782.520020 | 1585100 |
| 4 | 2016-11-08 | 783.400024 | 795.632996 | 780.190002 | 790.510010 | 790.510010 | 1350800 |
In [4]:
minmax = MinMaxScaler().fit(df.iloc[:, 4:5].astype('float32')) # Close index
df_log = minmax.transform(df.iloc[:, 4:5].astype('float32')) # Close index
df_log = pd.DataFrame(df_log)
df_log.head()
Out[4]:
| 0 | |
| 0 | 0.112708 |
| 1 | 0.090008 |
| 2 | 0.089628 |
| 3 | 0.160459 |
| 4 | 0.188066 |
Split train and test
I will cut the dataset to train and test the datasets,
Training dataset derived from start timestamp until last 30 days
Test dataset derived from the last 30 days until the end of the dataset
So we will let the model do forecasting based on the last 30 days, and we will going to repeat the experiment 10 times. You can increase it locally if you want, and tuning parameters will help you a lot.
In [5]:
test_size = 30
simulation_size = 10
df_train = df_log.iloc[:-test_size]
df_test = df_log.iloc[-test_size:]
df.shape, df_train.shape, df_test.shape
Out[5]:
((252, 7), (222, 1), (30, 1))
In [6]:
class Model:
def __init__(
self,
learning_rate,
num_layers,
size,
size_layer,
output_size,
forget_bias = 0.1,
lambda_coeff = 0.5
):
def lstm_cell(size_layer):
return tf.nn.rnn_cell.GRUCell(size_layer)
rnn_cells = tf.nn.rnn_cell.MultiRNNCell(
[lstm_cell(size_layer) for _ in range(num_layers)],
state_is_tuple = False,
)
self.X = tf.placeholder(tf.float32, (None, None, size))
self.Y = tf.placeholder(tf.float32, (None, output_size))
drop = tf.contrib.rnn.DropoutWrapper(
rnn_cells, output_keep_prob = forget_bias
)
self.hidden_layer = tf.placeholder(
tf.float32, (None, num_layers * size_layer)
)
_, last_state = tf.nn.dynamic_rnn(
drop, self.X, initial_state = self.hidden_layer, dtype = tf.float32
)
self.z_mean = tf.layers.dense(last_state, size)
self.z_log_sigma = tf.layers.dense(last_state, size)
epsilon = tf.random_normal(tf.shape(self.z_log_sigma))
self.z_vector = self.z_mean + tf.exp(self.z_log_sigma)
with tf.variable_scope('decoder', reuse = False):
rnn_cells_dec = tf.nn.rnn_cell.MultiRNNCell(
[lstm_cell(size_layer) for _ in range(num_layers)], state_is_tuple = False
)
drop_dec = tf.contrib.rnn.DropoutWrapper(
rnn_cells_dec, output_keep_prob = forget_bias
)
x = tf.concat([tf.expand_dims(self.z_vector, axis=0), self.X], axis = 1)
self.outputs, self.last_state = tf.nn.dynamic_rnn(
drop_dec, self.X, initial_state = last_state, dtype = tf.float32
)
self.logits = tf.layers.dense(self.outputs[-1], output_size)
self.lambda_coeff = lambda_coeff
self.kl_loss = -0.5 * tf.reduce_sum(1.0 + 2 * self.z_log_sigma - self.z_mean ** 2 -
tf.exp(2 * self.z_log_sigma), 1)
self.kl_loss = tf.scalar_mul(self.lambda_coeff, self.kl_loss)
self.cost = tf.reduce_mean(tf.square(self.Y - self.logits) + self.kl_loss)
self.optimizer = tf.train.AdamOptimizer(learning_rate).minimize(
self.cost
)
def calculate_accuracy(real, predict):
real = np.array(real) + 1
predict = np.array(predict) + 1
percentage = 1 - np.sqrt(np.mean(np.square((real - predict) / real)))
return percentage * 100
def anchor(signal, weight):
buffer = []
last = signal[0]
for i in signal:
smoothed_val = last * weight + (1 - weight) * i
buffer.append(smoothed_val)
last = smoothed_val
return buffer
In [7]:
num_layers = 1
size_layer = 128
timestamp = 5
epoch = 300
dropout_rate = 0.8
future_day = test_size
learning_rate = 0.01
In [8]:
def forecast():
tf.reset_default_graph()
modelnn = Model(
learning_rate, num_layers, df_log.shape[1], size_layer, df_log.shape[1], dropout_rate
)
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
date_ori = pd.to_datetime(df.iloc[:, 0]).tolist()
pbar = tqdm(range(epoch), desc = 'train loop')
for i in pbar:
init_value = np.zeros((1, num_layers * size_layer))
total_loss, total_acc = [], []
for k in range(0, df_train.shape[0] - 1, timestamp):
index = min(k + timestamp, df_train.shape[0] - 1)
batch_x = np.expand_dims(
df_train.iloc[k : index, :].values, axis = 0
)
batch_x = np.random.binomial(1, 0.5, batch_x.shape) * batch_x
batch_y = df_train.iloc[k + 1 : index + 1, :].values
logits, last_state, _, loss = sess.run(
[modelnn.logits, modelnn.last_state, modelnn.optimizer, modelnn.cost],
feed_dict = {
modelnn.X: batch_x,
modelnn.Y: batch_y,
modelnn.hidden_layer: init_value,
},
)
init_value = last_state
total_loss.append(loss)
total_acc.append(calculate_accuracy(batch_y[:, 0], logits[:, 0]))
pbar.set_postfix(cost = np.mean(total_loss), acc = np.mean(total_acc))
future_day = test_size
output_predict = np.zeros((df_train.shape[0] + future_day, df_train.shape[1]))
output_predict[0] = df_train.iloc[0]
upper_b = (df_train.shape[0] // timestamp) * timestamp
init_value = np.zeros((1, num_layers * size_layer))
for k in range(0, (df_train.shape[0] // timestamp) * timestamp, timestamp):
out_logits, last_state = sess.run(
[modelnn.logits, modelnn.last_state],
feed_dict = {
modelnn.X: np.expand_dims(
df_train.iloc[k : k + timestamp], axis = 0
),
modelnn.hidden_layer: init_value,
},
)
init_value = last_state
output_predict[k + 1 : k + timestamp + 1] = out_logits
if upper_b != df_train.shape[0]:
out_logits, last_state = sess.run(
[modelnn.logits, modelnn.last_state],
feed_dict = {
modelnn.X: np.expand_dims(df_train.iloc[upper_b:], axis = 0),
modelnn.hidden_layer: init_value,
},
)
output_predict[upper_b + 1 : df_train.shape[0] + 1] = out_logits
future_day -= 1
date_ori.append(date_ori[-1] + timedelta(days = 1))
init_value = last_state
for i in range(future_day):
o = output_predict[-future_day - timestamp + i:-future_day + i]
out_logits, last_state = sess.run(
[modelnn.logits, modelnn.last_state],
feed_dict = {
modelnn.X: np.expand_dims(o, axis = 0),
modelnn.hidden_layer: init_value,
},
)
init_value = last_state
output_predict[-future_day + i] = out_logits[-1]
date_ori.append(date_ori[-1] + timedelta(days = 1))
output_predict = minmax.inverse_transform(output_predict)
deep_future = anchor(output_predict[:, 0], 0.3)
return deep_future[-test_size:]
In [9]:
results = []
for i in range(simulation_size):
print('simulation %d'%(i + 1))
results.append(forecast())
WARNING: Logging before flag parsing goes to stderr.
W0816 23:54:04.861056 140552998012736 deprecation.py:323] From <ipython-input-6-f18f06dc1a5f>:13: GRUCell.__init__ (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.
Instructions for updating:
This class is equivalent as tf.keras.layers.GRUCell, and will be replaced by that in Tensorflow 2.0.
W0816 23:54:04.862557 140552998012736 deprecation.py:323] From <ipython-input-6-f18f06dc1a5f>:17: MultiRNNCell.__init__ (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.
Instructions for updating:
This class is equivalent as tf.keras.layers.StackedRNNCells, and will be replaced by that in Tensorflow 2.0.
simulation 1
W0816 23:54:05.179484 140552998012736 lazy_loader.py:50]
The TensorFlow contrib module will not be included in TensorFlow 2.0.
For more information, please see:
* https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
* https://github.com/tensorflow/addons
* https://github.com/tensorflow/io (for I/O related ops)
If you depend on functionality not listed there, please file an issue.
W0816 23:54:05.182720 140552998012736 deprecation.py:323] From <ipython-input-6-f18f06dc1a5f>:28: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.
Instructions for updating:
Please use `keras.layers.RNN(cell)`, which is equivalent to this API
W0816 23:54:05.374030 140552998012736 deprecation.py:506] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/init_ops.py:1251: calling VarianceScaling.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
W0816 23:54:05.380675 140552998012736 deprecation.py:506] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/rnn_cell_impl.py:564: calling Constant.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
W0816 23:54:05.389776 140552998012736 deprecation.py:506] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/rnn_cell_impl.py:574: calling Zeros.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
W0816 23:54:05.536239 140552998012736 deprecation.py:323] From <ipython-input-6-f18f06dc1a5f>:31: dense (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.dense instead.
W0816 23:54:05.986564 140552998012736 deprecation.py:323] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/math_grad.py:1205: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
train loop: 100%|██████████| 300/300 [01:48<00:00, 2.73it/s, acc=96, cost=0.00448]
simulation 2
train loop: 100%|██████████| 300/300 [01:49<00:00, 2.74it/s, acc=95.6, cost=0.00512]
simulation 3
train loop: 100%|██████████| 300/300 [01:48<00:00, 2.76it/s, acc=96.2, cost=0.0037]
simulation 4
train loop: 100%|██████████| 300/300 [01:48<00:00, 2.75it/s, acc=95.5, cost=0.00715]
simulation 5
train loop: 100%|██████████| 300/300 [01:48<00:00, 2.78it/s, acc=96.6, cost=0.0041]
simulation 6
train loop: 100%|██████████| 300/300 [01:48<00:00, 2.75it/s, acc=97.3, cost=0.00204]
simulation 7
train loop: 100%|██████████| 300/300 [01:47<00:00, 2.81it/s, acc=62, cost=7.74]
simulation 8
train loop: 100%|██████████| 300/300 [01:48<00:00, 2.80it/s, acc=95, cost=0.00699]
simulation 9
train loop: 100%|██████████| 300/300 [01:48<00:00, 2.76it/s, acc=96.8, cost=0.00279]
simulation 10
train loop: 100%|██████████| 300/300 [01:48<00:00, 2.75it/s, acc=97.1, cost=0.00215]
In [10]:
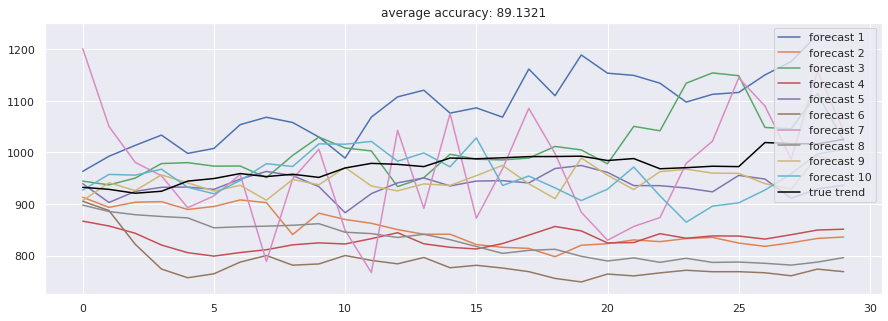
accuracies = [calculate_accuracy(df['Close'].iloc[-test_size:].values, r) for r in results]
plt.figure(figsize = (15, 5))
for no, r in enumerate(results):
plt.plot(r, label = 'forecast %d'%(no + 1))
plt.plot(df['Close'].iloc[-test_size:].values, label = 'true trend', c = 'black')
plt.legend()
plt.title('average accuracy: %.4f'%(np.mean(accuracies)))
plt.show()
Requirements
import sys
import warnings
if not sys.warnoptions:
warnings.simplefilter('ignore')
In [2]:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from datetime import datetime
from datetime import timedelta
from tqdm import tqdm
sns.set()
tf.compat.v1.random.set_random_seed(1234)
In [3]:
df = pd.read_csv('../dataset/GOOG-year.csv')
df.head()
Out[3]:
| Date | Open | High | Low | Close | Adj Close | Volume | |
| 0 | 2016-11-02 | 778.200012 | 781.650024 | 763.450012 | 768.700012 | 768.700012 | 1872400 |
| 1 | 2016-11-03 | 767.250000 | 769.950012 | 759.030029 | 762.130005 | 762.130005 | 1943200 |
| 2 | 2016-11-04 | 750.659973 | 770.359985 | 750.560974 | 762.020020 | 762.020020 | 2134800 |
| 3 | 2016-11-07 | 774.500000 | 785.190002 | 772.549988 | 782.520020 | 782.520020 | 1585100 |
| 4 | 2016-11-08 | 783.400024 | 795.632996 | 780.190002 | 790.510010 | 790.510010 | 1350800 |
In [4]:
minmax = MinMaxScaler().fit(df.iloc[:, 4:5].astype('float32')) # Close index
df_log = minmax.transform(df.iloc[:, 4:5].astype('float32')) # Close index
df_log = pd.DataFrame(df_log)
df_log.head()
Out[4]:
| 0 | |
| 0 | 0.112708 |
| 1 | 0.090008 |
| 2 | 0.089628 |
| 3 | 0.160459 |
| 4 | 0.188066 |
Split train and test
I will cut the dataset to train and test the datasets,
Training dataset derived from start timestamp until last 30 days
Test dataset derived from the last 30 days until the end of the dataset
We will let the model do forecasting based on the last 30 days and we are going to repeat the experiment 10 times. You can increase it locally if you want, and tuning parameters will help you a lot.
In [5]:
test_size = 30
simulation_size = 10
df_train = df_log.iloc[:-test_size]
df_test = df_log.iloc[-test_size:]
df.shape, df_train.shape, df_test.shape
Out[5]:
((252, 7), (222, 1), (30, 1))
In [6]:
def layer_norm(inputs, epsilon=1e-8):
mean, variance = tf.nn.moments(inputs, [-1], keep_dims=True)
normalized = (inputs - mean) / (tf.sqrt(variance + epsilon))
params_shape = inputs.get_shape()[-1:]
gamma = tf.get_variable('gamma', params_shape, tf.float32, tf.ones_initializer())
beta = tf.get_variable('beta', params_shape, tf.float32, tf.zeros_initializer())
outputs = gamma * normalized + beta
return outputs
def multihead_attn(queries, keys, q_masks, k_masks, future_binding, num_units, num_heads):
T_q = tf.shape(queries)[1]
T_k = tf.shape(keys)[1]
Q = tf.layers.dense(queries, num_units, name='Q')
K_V = tf.layers.dense(keys, 2*num_units, name='K_V')
K, V = tf.split(K_V, 2, -1)
Q_ = tf.concat(tf.split(Q, num_heads, axis=2), axis=0)
K_ = tf.concat(tf.split(K, num_heads, axis=2), axis=0)
V_ = tf.concat(tf.split(V, num_heads, axis=2), axis=0)
align = tf.matmul(Q_, tf.transpose(K_, [0,2,1]))
align = align / np.sqrt(K_.get_shape().as_list()[-1])
paddings = tf.fill(tf.shape(align), float('-inf'))
key_masks = k_masks
key_masks = tf.tile(key_masks, [num_heads, 1])
key_masks = tf.tile(tf.expand_dims(key_masks, 1), [1, T_q, 1])
align = tf.where(tf.equal(key_masks, 0), paddings, align)
if future_binding:
lower_tri = tf.ones([T_q, T_k])
lower_tri = tf.linalg.LinearOperatorLowerTriangular(lower_tri).to_dense()
masks = tf.tile(tf.expand_dims(lower_tri,0), [tf.shape(align)[0], 1, 1])
align = tf.where(tf.equal(masks, 0), paddings, align)
align = tf.nn.softmax(align)
query_masks = tf.to_float(q_masks)
query_masks = tf.tile(query_masks, [num_heads, 1])
query_masks = tf.tile(tf.expand_dims(query_masks, -1), [1, 1, T_k])
align *= query_masks
outputs = tf.matmul(align, V_)
outputs = tf.concat(tf.split(outputs, num_heads, axis=0), axis=2)
outputs += queries
outputs = layer_norm(outputs)
return outputs
def pointwise_feedforward(inputs, hidden_units, activation=None):
outputs = tf.layers.dense(inputs, 4*hidden_units, activation=activation)
outputs = tf.layers.dense(outputs, hidden_units, activation=None)
outputs += inputs
outputs = layer_norm(outputs)
return outputs
def learned_position_encoding(inputs, mask, embed_dim):
T = tf.shape(inputs)[1]
outputs = tf.range(tf.shape(inputs)[1]) # (T_q)
outputs = tf.expand_dims(outputs, 0) # (1, T_q)
outputs = tf.tile(outputs, [tf.shape(inputs)[0], 1]) # (N, T_q)
outputs = embed_seq(outputs, T, embed_dim, zero_pad=False, scale=False)
return tf.expand_dims(tf.to_float(mask), -1) * outputs
def sinusoidal_position_encoding(inputs, mask, repr_dim):
T = tf.shape(inputs)[1]
pos = tf.reshape(tf.range(0.0, tf.to_float(T), dtype=tf.float32), [-1, 1])
i = np.arange(0, repr_dim, 2, np.float32)
denom = np.reshape(np.power(10000.0, i / repr_dim), [1, -1])
enc = tf.expand_dims(tf.concat([tf.sin(pos / denom), tf.cos(pos / denom)], 1), 0)
return tf.tile(enc, [tf.shape(inputs)[0], 1, 1]) * tf.expand_dims(tf.to_float(mask), -1)
def label_smoothing(inputs, epsilon=0.1):
C = inputs.get_shape().as_list()[-1]
return ((1 - epsilon) * inputs) + (epsilon / C)
class Attention:
def __init__(self, size_layer, embedded_size, learning_rate, size, output_size,
num_blocks = 2,
num_heads = 8,
min_freq = 50):
self.X = tf.placeholder(tf.float32, (None, None, size))
self.Y = tf.placeholder(tf.float32, (None, output_size))
encoder_embedded = tf.layers.dense(self.X, embedded_size)
encoder_embedded = tf.nn.dropout(encoder_embedded, keep_prob = 0.8)
x_mean = tf.reduce_mean(self.X, axis = 2)
en_masks = tf.sign(x_mean)
encoder_embedded += sinusoidal_position_encoding(self.X, en_masks, embedded_size)
for i in range(num_blocks):
with tf.variable_scope('encoder_self_attn_%d'%i,reuse=tf.AUTO_REUSE):
encoder_embedded = multihead_attn(queries = encoder_embedded,
keys = encoder_embedded,
q_masks = en_masks,
k_masks = en_masks,
future_binding = False,
num_units = size_layer,
num_heads = num_heads)
with tf.variable_scope('encoder_feedforward_%d'%i,reuse=tf.AUTO_REUSE):
encoder_embedded = pointwise_feedforward(encoder_embedded,
embedded_size,
activation = tf.nn.relu)
self.logits = tf.layers.dense(encoder_embedded[-1], output_size)
self.cost = tf.reduce_mean(tf.square(self.Y - self.logits))
self.optimizer = tf.train.AdamOptimizer(learning_rate).minimize(
self.cost
)
def calculate_accuracy(real, predict):
real = np.array(real) + 1
predict = np.array(predict) + 1
percentage = 1 - np.sqrt(np.mean(np.square((real - predict) / real)))
return percentage * 100
def anchor(signal, weight):
buffer = []
last = signal[0]
for i in signal:
smoothed_val = last * weight + (1 - weight) * i
buffer.append(smoothed_val)
last = smoothed_val
return buffer
In [7]:
num_layers = 1
size_layer = 128
timestamp = 5
epoch = 300
dropout_rate = 0.8
future_day = test_size
learning_rate = 0.001
In [8]:
def forecast():
tf.reset_default_graph()
modelnn = Attention(size_layer, size_layer, learning_rate, df_log.shape[1], df_log.shape[1])
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
date_ori = pd.to_datetime(df.iloc[:, 0]).tolist()
pbar = tqdm(range(epoch), desc = 'train loop')
for i in pbar:
total_loss, total_acc = [], []
for k in range(0, df_train.shape[0] - 1, timestamp):
index = min(k + timestamp, df_train.shape[0] - 1)
batch_x = np.expand_dims(
df_train.iloc[k : index, :].values, axis = 0
)
batch_y = df_train.iloc[k + 1 : index + 1, :].values
logits, _, loss = sess.run(
[modelnn.logits, modelnn.optimizer, modelnn.cost],
feed_dict = {
modelnn.X: batch_x,
modelnn.Y: batch_y
},
)
total_loss.append(loss)
total_acc.append(calculate_accuracy(batch_y[:, 0], logits[:, 0]))
pbar.set_postfix(cost = np.mean(total_loss), acc = np.mean(total_acc))
future_day = test_size
output_predict = np.zeros((df_train.shape[0] + future_day, df_train.shape[1]))
output_predict[0] = df_train.iloc[0]
upper_b = (df_train.shape[0] // timestamp) * timestamp
for k in range(0, (df_train.shape[0] // timestamp) * timestamp, timestamp):
out_logits = sess.run(
modelnn.logits,
feed_dict = {
modelnn.X: np.expand_dims(
df_train.iloc[k : k + timestamp], axis = 0
)
},
)
output_predict[k + 1 : k + timestamp + 1] = out_logits
if upper_b != df_train.shape[0]:
out_logits = sess.run(
modelnn.logits,
feed_dict = {
modelnn.X: np.expand_dims(df_train.iloc[upper_b:], axis = 0)
},
)
output_predict[upper_b + 1 : df_train.shape[0] + 1] = out_logits
future_day -= 1
date_ori.append(date_ori[-1] + timedelta(days = 1))
for i in range(future_day):
o = output_predict[-future_day - timestamp + i:-future_day + i]
out_logits = sess.run(
modelnn.logits,
feed_dict = {
modelnn.X: np.expand_dims(o, axis = 0)
},
)
output_predict[-future_day + i] = out_logits[-1]
date_ori.append(date_ori[-1] + timedelta(days = 1))
output_predict = minmax.inverse_transform(output_predict)
deep_future = anchor(output_predict[:, 0], 0.3)
return deep_future[-test_size:]
In [9]:
results = []
for i in range(simulation_size):
print('simulation %d'%(i + 1))
results.append(forecast())
WARNING: Logging before flag parsing goes to stderr.
W0817 12:08:12.096583 140064997701440 deprecation.py:323] From <ipython-input-6-24d2a24c36ef>:91: dense (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.dense instead.
W0817 12:08:12.104836 140064997701440 deprecation.py:506] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/init_ops.py:1251: calling VarianceScaling.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
simulation 1
W0817 12:08:12.294501 140064997701440 deprecation.py:506] From <ipython-input-6-24d2a24c36ef>:92: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
W0817 12:08:12.305350 140064997701440 deprecation.py:323] From <ipython-input-6-24d2a24c36ef>:73: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.cast` instead.
W0817 12:08:12.446460 140064997701440 deprecation.py:323] From <ipython-input-6-24d2a24c36ef>:33: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
train loop: 100%|██████████| 300/300 [01:41<00:00, 2.97it/s, acc=96.7, cost=0.00409]
simulation 2
train loop: 100%|██████████| 300/300 [01:40<00:00, 2.99it/s, acc=97.3, cost=0.00184]
simulation 3
train loop: 100%|██████████| 300/300 [01:40<00:00, 2.98it/s, acc=96.7, cost=0.00351]
simulation 4
train loop: 100%|██████████| 300/300 [01:40<00:00, 2.98it/s, acc=97.9, cost=0.00112]
simulation 5
train loop: 100%|██████████| 300/300 [01:41<00:00, 2.97it/s, acc=98, cost=0.00113]
simulation 6
train loop: 100%|██████████| 300/300 [01:40<00:00, 2.98it/s, acc=97.5, cost=0.00165]
simulation 7
train loop: 100%|██████████| 300/300 [01:41<00:00, 2.96it/s, acc=95.8, cost=0.00513]
simulation 9
train loop: 100%|██████████| 300/300 [01:41<00:00, 2.98it/s, acc=98, cost=0.000974]
simulation 10
train loop: 100%|██████████| 300/300 [01:40<00:00, 2.99it/s, acc=96.8, cost=0.00322]
In [10]:
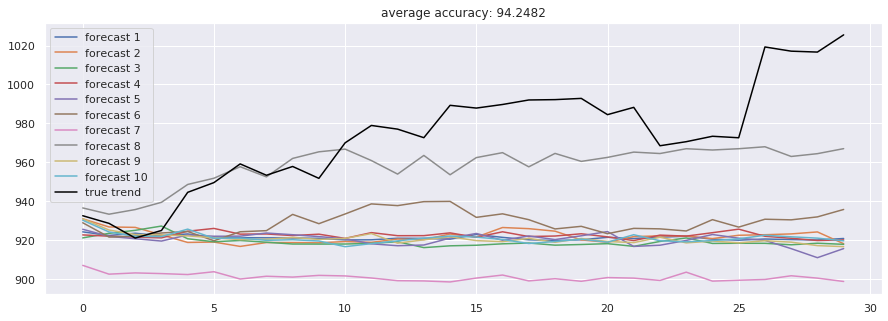
accuracies = [calculate_accuracy(df['Close'].iloc[-test_size:].values, r) for r in results]
plt.figure(figsize = (15, 5))
for no, r in enumerate(results):
plt.plot(r, label = 'forecast %d'%(no + 1))
plt.plot(df['Close'].iloc[-test_size:].values, label = 'true trend', c = 'black')
plt.legend()
plt.title('average accuracy: %.4f'%(np.mean(accuracies)))
plt.show()
CNN seq2seq
import sys
import warnings
if not sys.warnoptions:
warnings.simplefilter('ignore')
In [2]:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from datetime import datetime
from datetime import timedelta
from tqdm import tqdm
sns.set()
tf.compat.v1.random.set_random_seed(1234)
In [3]:
df = pd.read_csv('../dataset/GOOG-year.csv')
df.head()
Out[3]:
| Date | Open | High | Low | Close | Adj Close | Volume | |
| 0 | 2016-11-02 | 778.200012 | 781.650024 | 763.450012 | 768.700012 | 768.700012 | 1872400 |
| 1 | 2016-11-03 | 767.250000 | 769.950012 | 759.030029 | 762.130005 | 762.130005 | 1943200 |
| 2 | 2016-11-04 | 750.659973 | 770.359985 | 750.560974 | 762.020020 | 762.020020 | 2134800 |
| 3 | 2016-11-07 | 774.500000 | 785.190002 | 772.549988 | 782.520020 | 782.520020 | 1585100 |
| 4 | 2016-11-08 | 783.400024 | 795.632996 | 780.190002 | 790.510010 | 790.510010 | 1350800 |
In [4]:
minmax = MinMaxScaler().fit(df.iloc[:, 4:5].astype('float32')) # Close index
df_log = minmax.transform(df.iloc[:, 4:5].astype('float32')) # Close index
df_log = pd.DataFrame(df_log)
df_log.head()
Out[4]:
| 0 | |
| 0 | 0.112708 |
| 1 | 0.090008 |
| 2 | 0.089628 |
| 3 | 0.160459 |
| 4 | 0.188066 |
Split train and test
I will cut the dataset to train and test the datasets,
Training dataset derived from the start timestamp until the last 30 days
Test dataset derived from the last 30 days until the end of the dataset
So we will let the model do forecasting based on the last 30 days, and we will going to repeat the experiment 10 times. You can increase it locally if you want, and tuning parameters will help you a lot.
In [5]:
test_size = 30
simulation_size = 10
df_train = df_log.iloc[:-test_size]
df_test = df_log.iloc[-test_size:]
df.shape, df_train.shape, df_test.shape
Out[5]:
((252, 7), (222, 1), (30, 1))
In [6]:
def encoder_block(inp, n_hidden, filter_size):
inp = tf.expand_dims(inp, 2)
inp = tf.pad(
inp,
[
[0, 0],
[(filter_size[0] - 1) // 2, (filter_size[0] - 1) // 2],
[0, 0],
[0, 0],
],
)
conv = tf.layers.conv2d(
inp, n_hidden, filter_size, padding = 'VALID', activation = None
)
conv = tf.squeeze(conv, 2)
return conv
def decoder_block(inp, n_hidden, filter_size):
inp = tf.expand_dims(inp, 2)
inp = tf.pad(inp, [[0, 0], [filter_size[0] - 1, 0], [0, 0], [0, 0]])
conv = tf.layers.conv2d(
inp, n_hidden, filter_size, padding = 'VALID', activation = None
)
conv = tf.squeeze(conv, 2)
return conv
def glu(x):
return tf.multiply(
x[:, :, : tf.shape(x)[2] // 2],
tf.sigmoid(x[:, :, tf.shape(x)[2] // 2 :]),
)
def layer(inp, conv_block, kernel_width, n_hidden, residual = None):
z = conv_block(inp, n_hidden, (kernel_width, 1))
return glu(z) + (residual if residual is not None else 0)
class Model:
def __init__(
self,
learning_rate,
num_layers,
size,
size_layer,
output_size,
kernel_size = 3,
n_attn_heads = 16,
dropout = 0.9,
):
self.X = tf.placeholder(tf.float32, (None, None, size))
self.Y = tf.placeholder(tf.float32, (None, output_size))
encoder_embedded = tf.layers.dense(self.X, size_layer)
e = tf.identity(encoder_embedded)
for i in range(num_layers):
z = layer(
encoder_embedded,
encoder_block,
kernel_size,
size_layer * 2,
encoder_embedded,
)
z = tf.nn.dropout(z, keep_prob = dropout)
encoder_embedded = z
encoder_output, output_memory = z, z + e
g = tf.identity(encoder_embedded)
for i in range(num_layers):
attn_res = h = layer(
encoder_embedded,
decoder_block,
kernel_size,
size_layer * 2,
residual = tf.zeros_like(encoder_embedded),
)
C = []
for j in range(n_attn_heads):
h_ = tf.layers.dense(h, size_layer // n_attn_heads)
g_ = tf.layers.dense(g, size_layer // n_attn_heads)
zu_ = tf.layers.dense(
encoder_output, size_layer // n_attn_heads
)
ze_ = tf.layers.dense(output_memory, size_layer // n_attn_heads)
d = tf.layers.dense(h_, size_layer // n_attn_heads) + g_
dz = tf.matmul(d, tf.transpose(zu_, [0, 2, 1]))
a = tf.nn.softmax(dz)
c_ = tf.matmul(a, ze_)
C.append(c_)
c = tf.concat(C, 2)
h = tf.layers.dense(attn_res + c, size_layer)
h = tf.nn.dropout(h, keep_prob = dropout)
encoder_embedded = h
encoder_embedded = tf.sigmoid(encoder_embedded[-1])
self.logits = tf.layers.dense(encoder_embedded, output_size)
self.cost = tf.reduce_mean(tf.square(self.Y - self.logits))
self.optimizer = tf.train.AdamOptimizer(learning_rate).minimize(
self.cost
)
def calculate_accuracy(real, predict):
real = np.array(real) + 1
predict = np.array(predict) + 1
percentage = 1 - np.sqrt(np.mean(np.square((real - predict) / real)))
return percentage * 100
def anchor(signal, weight):
buffer = []
last = signal[0]
for i in signal:
smoothed_val = last * weight + (1 - weight) * i
buffer.append(smoothed_val)
last = smoothed_val
return buffer
In [7]:
num_layers = 1
size_layer = 128
timestamp = test_size
epoch = 300
dropout_rate = 0.7
future_day = test_size
learning_rate = 1e-3
In [8]:
def forecast():
tf.reset_default_graph()
modelnn = Model(
learning_rate, num_layers, df_log.shape[1], size_layer, df_log.shape[1],
dropout = dropout_rate
)
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
date_ori = pd.to_datetime(df.iloc[:, 0]).tolist()
pbar = tqdm(range(epoch), desc = 'train loop')
for i in pbar:
init_value = np.zeros((1, num_layers * 2 * size_layer))
total_loss, total_acc = [], []
for k in range(0, df_train.shape[0] - 1, timestamp):
index = min(k + timestamp, df_train.shape[0] - 1)
batch_x = np.expand_dims(
df_train.iloc[k : index, :].values, axis = 0
)
batch_y = df_train.iloc[k + 1 : index + 1, :].values
logits, _, loss = sess.run(
[modelnn.logits, modelnn.optimizer, modelnn.cost],
feed_dict = {modelnn.X: batch_x, modelnn.Y: batch_y},
)
total_loss.append(loss)
total_acc.append(calculate_accuracy(batch_y[:, 0], logits[:, 0]))
pbar.set_postfix(cost = np.mean(total_loss), acc = np.mean(total_acc))
future_day = test_size
output_predict = np.zeros((df_train.shape[0] + future_day, df_train.shape[1]))
output_predict[0] = df_train.iloc[0]
upper_b = (df_train.shape[0] // timestamp) * timestamp
for k in range(0, (df_train.shape[0] // timestamp) * timestamp, timestamp):
out_logits = sess.run(
modelnn.logits,
feed_dict = {
modelnn.X: np.expand_dims(
df_train.iloc[k : k + timestamp], axis = 0
)
},
)
output_predict[k + 1 : k + timestamp + 1] = out_logits
if upper_b != df_train.shape[0]:
out_logits = sess.run(
modelnn.logits,
feed_dict = {
modelnn.X: np.expand_dims(df_train.iloc[upper_b:], axis = 0)
},
)
output_predict[upper_b + 1 : df_train.shape[0] + 1] = out_logits
future_day -= 1
date_ori.append(date_ori[-1] + timedelta(days = 1))
for i in range(future_day):
o = output_predict[-future_day - timestamp + i:-future_day + i]
out_logits = sess.run(
modelnn.logits,
feed_dict = {
modelnn.X: np.expand_dims(o, axis = 0)
},
)
output_predict[-future_day + i] = out_logits[-1]
date_ori.append(date_ori[-1] + timedelta(days = 1))
output_predict = minmax.inverse_transform(output_predict)
deep_future = anchor(output_predict[:, 0], 0.3)
return deep_future[-test_size:]
In [9]:
results = []
for i in range(simulation_size):
print('simulation %d'%(i + 1))
results.append(forecast())
WARNING: Logging before flag parsing goes to stderr.
W0818 16:16:28.504163 139649888855872 deprecation.py:323] From <ipython-input-6-6c0655f4345e>:55: dense (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.dense instead.
W0818 16:16:28.507718 139649888855872 deprecation.py:506] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/init_ops.py:1251: calling VarianceScaling.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
W0818 16:16:28.696973 139649888855872 deprecation.py:323] From <ipython-input-6-6c0655f4345e>:13: conv2d (from tensorflow.python.layers.convolutional) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.keras.layers.Conv2D` instead.
simulation 1
W0818 16:16:28.910956 139649888855872 deprecation.py:506] From <ipython-input-6-6c0655f4345e>:66: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
train loop: 100%|██████████| 300/300 [00:43<00:00, 7.09it/s, acc=96.6, cost=0.00251]
simulation 2
train loop: 100%|██████████| 300/300 [00:43<00:00, 7.08it/s, acc=96.9, cost=0.00232]
simulation 3
train loop: 100%|██████████| 300/300 [00:43<00:00, 6.99it/s, acc=94.1, cost=0.00764]
simulation 4
train loop: 100%|██████████| 300/300 [00:43<00:00, 6.98it/s, acc=96.6, cost=0.00273]
simulation 5
train loop: 100%|██████████| 300/300 [00:43<00:00, 7.02it/s, acc=97.7, cost=0.00113]
simulation 6
train loop: 100%|██████████| 300/300 [00:43<00:00, 7.06it/s, acc=97.7, cost=0.00117]
simulation 7
train loop: 100%|██████████| 300/300 [00:43<00:00, 6.98it/s, acc=96.4, cost=0.00286]
simulation 8
train loop: 100%|██████████| 300/300 [00:43<00:00, 6.97it/s, acc=94.7, cost=0.00573]
simulation 9
train loop: 100%|██████████| 300/300 [00:43<00:00, 6.94it/s, acc=93.9, cost=0.00807]
simulation 10
train loop: 100%|██████████| 300/300 [00:43<00:00, 7.05it/s, acc=94.6, cost=0.006]
In [10]:
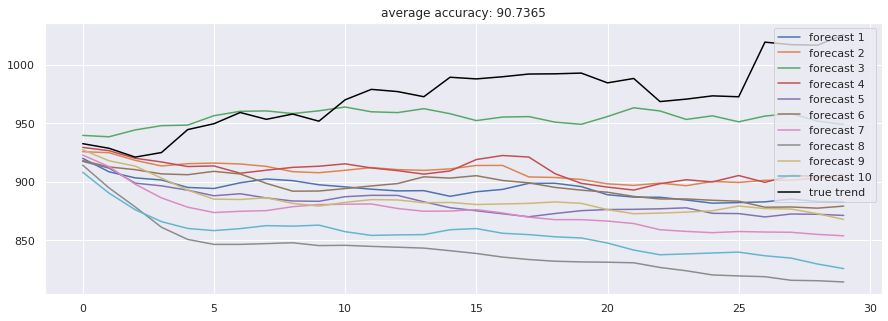
accuracies = [calculate_accuracy(df['Close'].iloc[-test_size:].values, r) for r in results]
plt.figure(figsize = (15, 5))
for no, r in enumerate(results):
plt.plot(r, label = 'forecast %d'%(no + 1))
plt.plot(df['Close'].iloc[-test_size:].values, label = 'true trend', c = 'black')
plt.legend()
plt.title('average accuracy: %.4f'%(np.mean(accuracies)))
plt.show()
Delayed CNN seq2seq
import sys
import warnings
if not sys.warnoptions:
warnings.simplefilter('ignore')
In [2]:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from datetime import datetime
from datetime import timedelta
from tqdm import tqdm
sns.set()
tf.compat.v1.random.set_random_seed(1234)
In [3]:
df = pd.read_csv('../dataset/GOOG-year.csv')
df.head()
Out[3]:
| Date | Open | High | Low | Close | Adj Close | Volume | |
| 0 | 2016-11-02 | 778.200012 | 781.650024 | 763.450012 | 768.700012 | 768.700012 | 1872400 |
| 1 | 2016-11-03 | 767.250000 | 769.950012 | 759.030029 | 762.130005 | 762.130005 | 1943200 |
| 2 | 2016-11-04 | 750.659973 | 770.359985 | 750.560974 | 762.020020 | 762.020020 | 2134800 |
| 3 | 2016-11-07 | 774.500000 | 785.190002 | 772.549988 | 782.520020 | 782.520020 | 1585100 |
| 4 | 2016-11-08 | 783.400024 | 795.632996 | 780.190002 | 790.510010 | 790.510010 | 1350800 |
In [4]:
minmax = MinMaxScaler().fit(df.iloc[:, 4:5].astype('float32')) # Close index
df_log = minmax.transform(df.iloc[:, 4:5].astype('float32')) # Close index
df_log = pd.DataFrame(df_log)
df_log.head()
Out[4]:
| 0 | |
| 0 | 0.112708 |
| 1 | 0.090008 |
| 2 | 0.089628 |
| 3 | 0.160459 |
| 4 | 0.188066 |
Split train and test
I will cut the dataset to train and test the datasets,
Training dataset derived from start timestamp until last 30 days
Test dataset derived from the last 30 days until the end of the dataset
We will let the model do forecasting based on the last 30 days and we are going to repeat the experiment 10 times. You can increase it locally if you want, and tuning parameters will help you a lot.
In [5]:
test_size = 30
simulation_size = 10
df_train = df_log.iloc[:-test_size]
df_test = df_log.iloc[-test_size:]
df.shape, df_train.shape, df_test.shape
Out[5]:
((252, 7), (222, 1), (30, 1))
In [6]:
def position_encoding(inputs):
T = tf.shape(inputs)[1]
repr_dim = inputs.get_shape()[-1].value
pos = tf.reshape(tf.range(0.0, tf.to_float(T), dtype=tf.float32), [-1, 1])
i = np.arange(0, repr_dim, 2, np.float32)
denom = np.reshape(np.power(10000.0, i / repr_dim), [1, -1])
enc = tf.expand_dims(tf.concat([tf.sin(pos / denom), tf.cos(pos / denom)], 1), 0)
return tf.tile(enc, [tf.shape(inputs)[0], 1, 1])
def layer_norm(inputs, epsilon=1e-8):
mean, variance = tf.nn.moments(inputs, [-1], keep_dims=True)
normalized = (inputs - mean) / (tf.sqrt(variance + epsilon))
params_shape = inputs.get_shape()[-1:]
gamma = tf.get_variable('gamma', params_shape, tf.float32, tf.ones_initializer())
beta = tf.get_variable('beta', params_shape, tf.float32, tf.zeros_initializer())
return gamma * normalized + beta
def cnn_block(x, dilation_rate, pad_sz, hidden_dim, kernel_size):
x = layer_norm(x)
pad = tf.zeros([tf.shape(x)[0], pad_sz, hidden_dim])
x = tf.layers.conv1d(inputs = tf.concat([pad, x, pad], 1),
filters = hidden_dim,
kernel_size = kernel_size,
dilation_rate = dilation_rate)
x = x[:, :-pad_sz, :]
x = tf.nn.relu(x)
return x
class Model:
def __init__(
self,
learning_rate,
num_layers,
size,
size_layer,
output_size,
kernel_size = 3,
n_attn_heads = 16,
dropout = 0.9,
):
self.X = tf.placeholder(tf.float32, (None, None, size))
self.Y = tf.placeholder(tf.float32, (None, output_size))
encoder_embedded = tf.layers.dense(self.X, size_layer)
encoder_embedded += position_encoding(encoder_embedded)
e = tf.identity(encoder_embedded)
for i in range(num_layers):
dilation_rate = 2 ** i
pad_sz = (kernel_size - 1) * dilation_rate
with tf.variable_scope('block_%d'%i):
encoder_embedded += cnn_block(encoder_embedded, dilation_rate,
pad_sz, size_layer, kernel_size)
encoder_output, output_memory = encoder_embedded, encoder_embedded + e
g = tf.identity(encoder_embedded)
for i in range(num_layers):
dilation_rate = 2 ** i
pad_sz = (kernel_size - 1) * dilation_rate
with tf.variable_scope('decode_%d'%i):
attn_res = h = cnn_block(encoder_embedded, dilation_rate,
pad_sz, size_layer, kernel_size)
C = []
for j in range(n_attn_heads):
h_ = tf.layers.dense(h, size_layer // n_attn_heads)
g_ = tf.layers.dense(g, size_layer // n_attn_heads)
zu_ = tf.layers.dense(
encoder_output, size_layer // n_attn_heads
)
ze_ = tf.layers.dense(output_memory, size_layer // n_attn_heads)
d = tf.layers.dense(h_, size_layer // n_attn_heads) + g_
dz = tf.matmul(d, tf.transpose(zu_, [0, 2, 1]))
a = tf.nn.softmax(dz)
c_ = tf.matmul(a, ze_)
C.append(c_)
c = tf.concat(C, 2)
h = tf.layers.dense(attn_res + c, size_layer)
h = tf.nn.dropout(h, keep_prob = dropout)
encoder_embedded += h
encoder_embedded = tf.sigmoid(encoder_embedded[-1])
self.logits = tf.layers.dense(encoder_embedded, output_size)
self.cost = tf.reduce_mean(tf.square(self.Y - self.logits))
self.optimizer = tf.train.AdamOptimizer(learning_rate).minimize(
self.cost
)
def calculate_accuracy(real, predict):
real = np.array(real) + 1
predict = np.array(predict) + 1
percentage = 1 - np.sqrt(np.mean(np.square((real - predict) / real)))
return percentage * 100
def anchor(signal, weight):
buffer = []
last = signal[0]
for i in signal:
smoothed_val = last * weight + (1 - weight) * i
buffer.append(smoothed_val)
last = smoothed_val
return buffer
In [7]:
num_layers = 1
size_layer = 128
timestamp = test_size
epoch = 300
dropout_rate = 0.8
future_day = test_size
learning_rate = 5e-4
In [8]:
def forecast():
tf.reset_default_graph()
modelnn = Model(
learning_rate, num_layers, df_log.shape[1], size_layer, df_log.shape[1],
dropout = dropout_rate
)
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
date_ori = pd.to_datetime(df.iloc[:, 0]).tolist()
pbar = tqdm(range(epoch), desc = 'train loop')
for i in pbar:
init_value = np.zeros((1, num_layers * 2 * size_layer))
total_loss, total_acc = [], []
for k in range(0, df_train.shape[0] - 1, timestamp):
index = min(k + timestamp, df_train.shape[0] - 1)
batch_x = np.expand_dims(
df_train.iloc[k : index, :].values, axis = 0
)
batch_y = df_train.iloc[k + 1 : index + 1, :].values
logits, _, loss = sess.run(
[modelnn.logits, modelnn.optimizer, modelnn.cost],
feed_dict = {modelnn.X: batch_x, modelnn.Y: batch_y},
)
total_loss.append(loss)
total_acc.append(calculate_accuracy(batch_y[:, 0], logits[:, 0]))
pbar.set_postfix(cost = np.mean(total_loss), acc = np.mean(total_acc))
future_day = test_size
output_predict = np.zeros((df_train.shape[0] + future_day, df_train.shape[1]))
output_predict[0] = df_train.iloc[0]
upper_b = (df_train.shape[0] // timestamp) * timestamp
for k in range(0, (df_train.shape[0] // timestamp) * timestamp, timestamp):
out_logits = sess.run(
modelnn.logits,
feed_dict = {
modelnn.X: np.expand_dims(
df_train.iloc[k : k + timestamp], axis = 0
)
},
)
output_predict[k + 1 : k + timestamp + 1] = out_logits
if upper_b != df_train.shape[0]:
out_logits = sess.run(
modelnn.logits,
feed_dict = {
modelnn.X: np.expand_dims(df_train.iloc[upper_b:], axis = 0)
},
)
output_predict[upper_b + 1 : df_train.shape[0] + 1] = out_logits
future_day -= 1
date_ori.append(date_ori[-1] + timedelta(days = 1))
for i in range(future_day):
o = output_predict[-future_day - timestamp + i:-future_day + i]
out_logits = sess.run(
modelnn.logits,
feed_dict = {
modelnn.X: np.expand_dims(o, axis = 0)
},
)
output_predict[-future_day + i] = out_logits[-1]
date_ori.append(date_ori[-1] + timedelta(days = 1))
output_predict = minmax.inverse_transform(output_predict)
deep_future = anchor(output_predict[:, 0], 0.3)
return deep_future[-test_size:]
In [9]:
results = []
for i in range(simulation_size):
print('simulation %d'%(i + 1))
results.append(forecast())
WARNING: Logging before flag parsing goes to stderr.
W0829 00:04:33.873839 140104212150080 deprecation.py:323] From <ipython-input-6-1aeaade5f897>:44: dense (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.dense instead.
W0829 00:04:33.883059 140104212150080 deprecation.py:506] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/init_ops.py:1251: calling VarianceScaling.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
simulation 1
W0829 00:04:34.265801 140104212150080 deprecation.py:323] From <ipython-input-6-1aeaade5f897>:4: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.cast` instead.
W0829 00:04:34.294613 140104212150080 deprecation.py:323] From <ipython-input-6-1aeaade5f897>:24: conv1d (from tensorflow.python.layers.convolutional) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.keras.layers.Conv1D` instead.
W0829 00:04:36.600379 140104212150080 deprecation.py:506] From <ipython-input-6-1aeaade5f897>:82: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
train loop: 100%|██████████| 300/300 [00:14<00:00, 20.69it/s, acc=93, cost=0.0106]
simulation 2
train loop: 100%|██████████| 300/300 [00:14<00:00, 20.99it/s, acc=97.6, cost=0.00116]
simulation 3
train loop: 100%|██████████| 300/300 [00:14<00:00, 20.94it/s, acc=95.2, cost=0.00553]
simulation 4
train loop: 100%|██████████| 300/300 [00:14<00:00, 20.97it/s, acc=95.4, cost=0.00442]
simulation 5
train loop: 100%|██████████| 300/300 [00:14<00:00, 21.88it/s, acc=95.6, cost=0.00393]
simulation 6
train loop: 100%|██████████| 300/300 [00:14<00:00, 21.01it/s, acc=95.3, cost=0.00454]
simulation 7
train loop: 100%|██████████| 300/300 [00:14<00:00, 21.05it/s, acc=96.7, cost=0.00229]
simulation 8
train loop: 100%|██████████| 300/300 [00:14<00:00, 21.01it/s, acc=97.1, cost=0.00178]
simulation 9
train loop: 100%|██████████| 300/300 [00:14<00:00, 20.80it/s, acc=95.3, cost=0.00492]
simulation 10
train loop: 100%|██████████| 300/300 [00:14<00:00, 20.94it/s, acc=90.6, cost=0.0192]
In [10]:
accuracies = [calculate_accuracy(df['Close'].iloc[-test_size:].values, r) for r in results]
plt.figure(figsize = (15, 5))
for no, r in enumerate(results):
plt.plot(r, label = 'forecast %d'%(no + 1))
plt.plot(df['Close'].iloc[-test_size:].values, label = 'true trend', c = 'black')
plt.legend()
plt.title('average accuracy: %.4f'%(np.mean(accuracies)))
plt.show()
Access
* `addressing.TemporalLinkage` to track the temporal ordering of writes in
memory for each write head.
* `addressing.FreenessAllocator` for keeping track of memory usage, where
usage increase when a memory location is written to, and decreases when
memory is read from that the controller says can be freed.
Write-address selection is done by an interpolation between content-based
lookup and using unused memory.
Read-address selection is done by an interpolation of content-based lookup
and following the link graph in the forward or backwards read direction.
"""
def __init__(self,
memory_size=128,
word_size=20,
num_reads=1,
num_writes=1,
name='memory_access'):
"""Creates a MemoryAccess module.
Args:
memory_size: The number of memory slots (N in the DNC paper).
word_size: The width of each memory slot (W in the DNC paper)
num_reads: The number of read heads (R in the DNC paper).
num_writes: The number of write heads (fixed at 1 in the paper).
name: The name of the module.
"""
super(MemoryAccess, self).__init__(name=name)
self._memory_size = memory_size
self._word_size = word_size
self._num_reads = num_reads
self._num_writes = num_writes
self._write_content_weights_mod = addressing.CosineWeights(
num_writes, word_size, name='write_content_weights')
self._read_content_weights_mod = addressing.CosineWeights(
num_reads, word_size, name='read_content_weights')
self._linkage = addressing.TemporalLinkage(memory_size, num_writes)
self._freeness = addressing.Freeness(memory_size)
def _build(self, inputs, prev_state):
"""Connects the MemoryAccess module into the graph.
Args:
inputs: tensor of shape `[batch_size, input_size]`. This is used to
control this access module.
prev_state: Instance of `AccessState` containing the previous state.
Returns:
A tuple `(output, next_state)`, where `output` is a tensor of shape
`[batch_size, num_reads, word_size]`, and `next_state` is the new
`AccessState` named tuple at the current time t.
"""
inputs = self._read_inputs(inputs)
# Update usage using inputs['free_gate'] and previous read & write weights.
usage = self._freeness(
write_weights=prev_state.write_weights,
free_gate=inputs['free_gate'],
read_weights=prev_state.read_weights,
prev_usage=prev_state.usage)
# Write to memory.
write_weights = self._write_weights(inputs, prev_state.memory, usage)
memory = _erase_and_write(
prev_state.memory,
address=write_weights,
reset_weights=inputs['erase_vectors'],
values=inputs['write_vectors'])
linkage_state = self._linkage(write_weights, prev_state.linkage)
# Read from memory.
read_weights = self._read_weights(
inputs,
memory=memory,
prev_read_weights=prev_state.read_weights,
link=linkage_state.link)
read_words = tf.matmul(read_weights, memory)
return (read_words, AccessState(
memory=memory,
read_weights=read_weights,
write_weights=write_weights,
linkage=linkage_state,
usage=usage))
def _read_inputs(self, inputs):
"""Applies transformations to `inputs` to get control for this module."""
def _linear(first_dim, second_dim, name, activation=None):
"""Returns a linear transformation of `inputs`, followed by a reshape."""
linear = snt.Linear(first_dim * second_dim, name=name)(inputs)
if activation is not None:
linear = activation(linear, name=name + '_activation')
return tf.reshape(linear, [-1, first_dim, second_dim])
# v_t^i - The vectors to write to memory, for each write head `i`.
write_vectors = _linear(self._num_writes, self._word_size, 'write_vectors')
# e_t^i - Amount to erase the memory by before writing, for each write head.
erase_vectors = _linear(self._num_writes, self._word_size, 'erase_vectors',
tf.sigmoid)
# f_t^j - Amount that the memory at the locations read from at the previous
# time step can be declared unused, for each read head `j`.
free_gate = tf.sigmoid(
snt.Linear(self._num_reads, name='free_gate')(inputs))
# g_t^{a, i} - Interpolation between writing to unallocated memory and
# content-based lookup, for each write head `i`. Note: `a` is simply used to
# identify this gate with allocation vs writing (as defined below).
allocation_gate = tf.sigmoid(
snt.Linear(self._num_writes, name='allocation_gate')(inputs))
# g_t^{w, i} - Overall gating of write amount for each write head.
write_gate = tf.sigmoid(
snt.Linear(self._num_writes, name='write_gate')(inputs))
# \pi_t^j - Mixing between "backwards" and "forwards" positions (for
# each write head), and content-based lookup, for each read head.
num_read_modes = 1 + 2 * self._num_writes
read_mode = snt.BatchApply(tf.nn.softmax)(
_linear(self._num_reads, num_read_modes, name='read_mode'))
# Parameters for the (read / write) "weights by content matching" modules.
write_keys = _linear(self._num_writes, self._word_size, 'write_keys')
write_strengths = snt.Linear(self._num_writes, name='write_strengths')(
inputs)
read_keys = _linear(self._num_reads, self._word_size, 'read_keys')
read_strengths = snt.Linear(self._num_reads, name='read_strengths')(inputs)
result = {
'read_content_keys': read_keys,
'read_content_strengths': read_strengths,
'write_content_keys': write_keys,
'write_content_strengths': write_strengths,
'write_vectors': write_vectors,
'erase_vectors': erase_vectors,
'free_gate': free_gate,
'allocation_gate': allocation_gate,
'write_gate': write_gate,
'read_mode': read_mode,
}
Return Results
def _write_weights(self, inputs, memory, usage):
"""Calculates the memory locations to write to.
This uses a combination of content-based lookups and finding an unused
location in memory, for each write head.
Args:
Inputs: Collection of inputs to the access module, including controls for
how to choose memory writing, such as the content to look-up and the
weighting between content-based and allocation-based addresses.
memory: A tensor of shape `[batch_size, memory_size, word_size]`
containing the current memory content.
usage: Current memory usage, which is a tensor of shape `[batch_size,
memory_size]`, used for allocation-based addressing.
Returns:
tensor of shape `[batch_size, num_writes, memory_size]` indicating where
to write to (if anywhere) for each writehead.
"""
with tf.name_scope('write_weights', values=[inputs, memory, usage]):
# c_t^{w, i} - The content-based weights for each write head.
write_content_weights = self._write_content_weights_mod(
memory, inputs['write_content_keys'],
inputs['write_content_strengths'])
# a_t^i - The allocation weights for each write head.
write_allocation_weights = self._freeness.write_allocation_weights(
usage=usage,
write_gates=(inputs['allocation_gate'] * inputs['write_gate']),
num_writes=self._num_writes)
# Expands gates over memory locations.
allocation_gate = tf.expand_dims(inputs['allocation_gate'], -1)
write_gate = tf.expand_dims(inputs['write_gate'], -1)
# w_t^{w, i} - The write weightings for each write head.
return write_gate * (allocation_gate * write_allocation_weights +
(1 - allocation_gate) * write_content_weights)
def _read_weights(self, inputs, memory, prev_read_weights, link):
"""Calculates read weights for each red head.
The reading weights are a combination of the following link graphs in the
forward or backward directions from the previous reading position, and doing
content-based lookup. The interpolation between these different modes is
done by `inputs['read_mode']`.
Args:
Inputs: Controls for this access module. This contains content-based
keys to lookup, and the weightings for the different reading modes.
memory: A tensor of shape `[batch_size, memory_size, word_size]`
containing the current memory content to do a content-based lookup.
prev_read_weights: A tensor of shape `[batch_size, num_reads,
memory_size]` containing the previously read locations.
link: A tensor of shape `[batch_size, num_writes, memory_size,
memory_size]` containing the temporal written transition graphs.
Returns:
A tensor of shape `[batch_size, num_reads, memory_size]` containing the
read weights for each readhead.
"""
with tf.name_scope(
'read_weights', values=[inputs, memory, prev_read_weights, link]):
# c_t^{r, i} - The content weightings for each read head.
content_weights = self._read_content_weights_mod(
memory, inputs['read_content_keys'], inputs['read_content_strengths'])
# Calculates f_t^i and b_t^i.
forward_weights = self._linkage.directional_read_weights(
link, prev_read_weights, forward=True)
backward_weights = self._linkage.directional_read_weights(
link, prev_read_weights, forward=False)
backward_mode = inputs['read_mode'][:, :, :self._num_writes]
forward_mode = (
inputs['read_mode'][:, :, self._num_writes:2 * self._num_writes])
content_mode = inputs['read_mode'][:, :, 2 * self._num_writes]
read_weights = (
tf.expand_dims(content_mode, 2) * content_weights + tf.reduce_sum(
tf.expand_dims(forward_mode, 3) * forward_weights, 2) +
tf.reduce_sum(tf.expand_dims(backward_mode, 3) * backward_weights, 2))
return read_weights
@property
def state_size(self):
"""Returns a tuple of the shape of the state tensors."""
Return AccessState (
memory=tf.TensorShape([self._memory_size, self._word_size]),
read_weights=tf.TensorShape([self._num_reads, self._memory_size]),
write_weights=tf.TensorShape([self._num_writes, self._memory_size]),
linkage=self._linkage.state_size,
usage=self._freeness.state_size)
@property
def output_size(self):
"""Returns the output shape."""
return tf.TensorShape([self._num_reads, self._word_size])
Addressing
link: tensor of shape `[batch_size, num_writes, memory_size,
memory_size]` representing the link graphs L_t.
prev_read_weights: tensor of shape `[batch_size, num_reads,
memory_size]` containing the previous read weights w_{t-1}^r.
forward: Boolean indicating whether to follow the "future" direction in
the link graph (True) or the "past" direction (False).
Returns:
tensor of shape `[batch_size, num_reads, num_writes, memory_size]`
"""
with tf.name_scope('directional_read_weights'):
# We calculate the forward and backward directions for each pair of
# read and write heads; hence we need to tile the read weights and do a
# sort of "outer product" to get this.
expanded_read_weights = tf.stack([prev_read_weights] * self._num_writes,
1)
result = tf.matmul(expanded_read_weights, link, adjoint_b=forward)
# Swap dimensions 1, 2 so order is [batch, reads, writes, memory]:
return tf.transpose(result, perm=[0, 2, 1, 3])
def _link(self, prev_link, prev_precedence_weights, write_weights):
"""Calculates the new link graphs.
For each write head, the link is a directed graph (represented by a matrix
with entries in range [0, 1]) whose vertices are the memory locations, and
an edge indicates temporal ordering of writes.
Args:
prev_link: A tensor of shape `[batch_size, num_writes, memory_size,
memory_size]` representing the previous link graphs for each write
head.
prev_precedence_weights: A tensor of shape `[batch_size, num_writes,
memory_size]` which is the previous "aggregated" write weights for
each write head.
write_weights: A tensor of shape `[batch_size, num_writes, memory_size]`
containing the new locations in memory written to.
Returns:
A tensor of shape `[batch_size, num_writes, memory_size, memory_size]`
containing the new link graphs for each write head.
"""
with tf.name_scope('link'):
batch_size = prev_link.get_shape()[0].value
write_weights_i = tf.expand_dims(write_weights, 3)
write_weights_j = tf.expand_dims(write_weights, 2)
prev_precedence_weights_j = tf.expand_dims(prev_precedence_weights, 2)
prev_link_scale = 1 - write_weights_i - write_weights_j
new_link = write_weights_i * prev_precedence_weights_j
link = prev_link_scale * prev_link + new_link
# Return the link with the diagonal set to zero, to remove self-looping
# edges.
return tf.matrix_set_diag(
link,
tf.zeros(
[batch_size, self._num_writes, self._memory_size],
dtype=link.dtype))
def _precedence_weights(self, prev_precedence_weights, write_weights):
"""Calculates the new precedence weights given the current write weights.
The precedence weights are the "aggregated write weights" for each write
head, where write weights with sum close to zero will leave the precedence
weights unchanged, but with sum close to one will replace the precedence
weights.
Args:
prev_precedence_weights: A tensor of shape `[batch_size, num_writes,
memory_size]` containing the previous precedence weights.
write_weights: A tensor of shape `[batch_size, num_writes, memory_size]`
containing the new write weights.
Returns:
A tensor of shape `[batch_size, num_writes, memory_size]` containing the
new precedence weights.
"""
with tf.name_scope('precedence_weights'):
write_sum = tf.reduce_sum(write_weights, 2, keep_dims=True)
return (1 - write_sum) * prev_precedence_weights + write_weights
@property
def state_size(self):
"""Returns a `TemporalLinkageState` tuple of the state tensors' shapes."""
return TemporalLinkageState(
link=tf.TensorShape(
[self._num_writes, self._memory_size, self._memory_size]),
precedence_weights=tf.TensorShape([self._num_writes,
self._memory_size]),)
class Freeness(snt.RNNCore):
""Memory usage that is increased by writing and decreased by reading.
This module is a pseudo-RNNCore whose state is a tensor with values in
the range [0, 1] indicating the usage of each of `memory_size` memory slots.
The usage is:
* Increased by writing, where usage is increased towards 1 at the write
addresses.
* Decreased by reading, where usage is decreased after reading from a
location when free_gate is close to 1.
The function `write_allocation_weights` can be invoked to get free locations
to write to for a number of written heads.
"""
def __init__(self, memory_size, name='freeness'):
"""Creates a Freeness module.
Args:
memory_size: Number of memory slots.
name: Name of the module.
"""
super(Freeness, self).__init__(name=name)
self._memory_size = memory_size
def _build(self, write_weights, free_gate, read_weights, prev_usage):
"""Calculates the new memory usage u_t.
Memory that was written to in the previous time step will have its usage
increased; memory that was read from and the controller says can be "freed"
will have its usage decreased.
Args:
write_weights: tensor of shape `[batch_size, num_writes,
memory_size]` giving write weights at previous time steps.
free_gate: tensor of shape `[batch_size, num_reads]` which indicates
which read heads read memories that can now be freed.
read_weights: tensor of shape `[batch_size, num_reads,
memory_size]` giving read weights at previous time step.
prev_usage: tensor of shape `[batch_size, memory_size]` giving
usage u_{t - 1} at the previous time step, with entries in range
[0, 1].
Returns:
tensor of shape `[batch_size, memory_size]` representing updated memory
usage.
"""
# Calculation of usage is not differentiable with respect to write weights.
write_weights = tf.stop_gradient(write_weights)
usage = self._usage_after_write(prev_usage, write_weights)
usage = self._usage_after_read(usage, free_gate, read_weights)
return usage
def write_allocation_weights(self, usage, write_gates, num_writes):
"""Calculates freeness-based locations for writing to.
This finds unused memory by ranking the memory locations by usage, for each
write head. (For more than one write head, we use a "simulated new usage"
which takes into account the fact that the previous write head will increase
the usage in that area of the memory.)
Args:
usage: A tensor of shape `[batch_size, memory_size]` representing
current memory usage.
write_gates: A tensor of shape `[batch_size, num_writes]` with values in
the range [0, 1] indicating how much each write head does writing
based on the address returned here (and hence how much usage
increases).
num_writes: The number of write heads to calculate write weights for.
Returns:
tensor of shape `[batch_size, num_writes, memory_size]` containing the
freeness-based writing locations. Note that this isn't scaled by
`write_gate`; this scaling must be applied externally.
"""
with tf.name_scope('write_allocation_weights'):
# expand gatings over memory locations
write_gates = tf.expand_dims(write_gates, -1)
allocation_weights = []
for i in range(num_writes):
allocation_weights.append(self._allocation(usage))
# update usage to take into account writing to this new allocation
usage += ((1 - usage) * write_gates[:, i, :] * allocation_weights[i])
# Pack the allocation weights for the write heads into one tensor.
return tf.stack(allocation_weights, axis=1)
def _usage_after_write(self, prev_usage, write_weights):
""Calcualtes the new usage after writing to memory.
Args:
prev_usage: tensor of shape `[batch_size, memory_size]`.
write_weights: tensor of shape `[batch_size, num_writes, memory_size]`.
Returns:
New usage, a tensor of shape `[batch_size, memory_size]`.
"""
with tf.name_scope('usage_after_write'):
# Calculate the aggregated effect of all writing heads
write_weights = 1 - tf.reduce_prod(1 - write_weights, [1])
return prev_usage + (1 - prev_usage) * write_weights
def _usage_after_read(self, prev_usage, free_gate, read_weights):
"""Calcualtes the new usage after reading and freeing from memory.
Args:
prev_usage: tensor of shape `[batch_size, memory_size]`.
free_gate: tensor of shape `[batch_size, num_reads]` with entries in the
range [0, 1] indicating the amount that locations read from can be
freed.
read_weights: tensor of shape `[batch_size, num_reads, memory_size]`.
Returns:
New usage, a tensor of shape `[batch_size, memory_size]`.
"""
with tf.name_scope('usage_after_read'):
free_gate = tf.expand_dims(free_gate, -1)
free_read_weights = free_gate * read_weights
phi = tf.reduce_prod(1 - free_read_weights, [1], name='phi')
return prev_usage * phi
def _allocation(self, usage):
r"""Computes allocation by sorting `usage`.
This corresponds to the value a = a_t[\phi_t[j]] in the paper.
Args:
usage: tensor of shape `[batch_size, memory_size]` indicating current
memory usage. This is equal to u_t in the paper when we only have one
write head, but for multiple write heads, one should update the usage
while iterating through the write heads to take into account the
allocation returned by this function.
Returns:
Tensor of shape `[batch_size, memory_size]` corresponding to allocation.
"""
with tf.name_scope('allocation'):
# Ensure values are not too small prior to cumprod.
usage = _EPSILON + (1 - _EPSILON) * usage
nonusage = 1 - usage
sorted_nonusage, indices = tf.nn.top_k(
nonusage, k=self._memory_size, name='sort')
sorted_usage = 1 - sorted_nonusage
prod_sorted_usage = tf.cumprod(sorted_usage, axis=1, exclusive=True)
sorted_allocation = sorted_nonusage * prod_sorted_usage
inverse_indices = util.batch_invert_permutation(indices)
# This final line "unsorts" sorted_allocation, so that the indexing
# corresponds to the original indexing of `usage`.
return util.batch_gather(sorted_allocation, inverse_indices)
@property
def state_size(self):
"""Returns the shape of the state tensor."""
return tf.TensorShape([self._memory_size])
Auto coder
import tensorflow as tf
import numpy as np
import time
def reducedimension(input_, dimension = 2, learning_rate = 0.01, hidden_layer = 256, epoch = 20):
input_size = input_.shape[1]
X = tf.placeholder("float", [None, input_size])
weights = {
'encoder_h1': tf.Variable(tf.random_normal([input_size, hidden_layer])),
'encoder_h2': tf.Variable(tf.random_normal([hidden_layer, dimension])),
'decoder_h1': tf.Variable(tf.random_normal([dimension, hidden_layer])),
'decoder_h2': tf.Variable(tf.random_normal([hidden_layer, input_size])),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([hidden_layer])),
'encoder_b2': tf.Variable(tf.random_normal([dimension])),
'decoder_b1': tf.Variable(tf.random_normal([hidden_layer])),
'decoder_b2': tf.Variable(tf.random_normal([input_size])),
}
first_layer_encoder = tf.nn.sigmoid(tf.add(tf.matmul(X, weights['encoder_h1']), biases['encoder_b1']))
second_layer_encoder = tf.nn.sigmoid(tf.add(tf.matmul(first_layer_encoder, weights['encoder_h2']), biases['encoder_b2']))
first_layer_decoder = tf.nn.sigmoid(tf.add(tf.matmul(second_layer_encoder, weights['decoder_h1']), biases['decoder_b1']))
second_layer_decoder = tf.nn.sigmoid(tf.add(tf.matmul(first_layer_decoder, weights['decoder_h2']), biases['decoder_b2']))
cost = tf.reduce_mean(tf.pow(X - second_layer_decoder, 2))
optimizer = tf.train.RMSPropOptimizer(learning_rate).minimize(cost)
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
for i in range(epoch):
last_time = time.time()
_, loss = sess.run([optimizer, cost], feed_dict={X: input_})
if (i + 1) % 10 == 0:
print('epoch:', i + 1, 'loss:', loss, 'time:', time.time() - last_time)
vectors = sess.run(second_layer_encoder, feed_dict={X: input_})
tf.reset_default_graph()
return vectors
DNC
Copyright 2017 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""DNC Cores.
These modules create a DNC core. They take input, pass parameters to the memory
access module, and integrate the output of memory to form an output.
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import collections
import numpy as np
import sonnet as snt
import tensorflow as tf
import access
DNCState = collections.namedtuple('DNCState', ('access_output', 'access_state',
'controller_state'))
class DNC(snt.RNNCore):
"""DNC core module.
Contains controller and memory access module.
"""
def __init__(self,
access_config,
controller_config,
output_size,
clip_value=None,
name='dnc'):
"""Initializes the DNC core.
Args:
access_config: dictionary of access module configurations.
controller_config: dictionary of controller (LSTM) module configurations.
output_size: output dimension size of core.
clip_value: clips controller and core output values to between
`[-clip_value, clip_value]` if specified.
name: module name (default 'dnc').
Raises:
TypeError: if direct_input_size is not None for any access module other
than KeyValueMemory.
"""
super(DNC, self).__init__(name=name)
with self._enter_variable_scope():
self._controller = snt.LSTM(**controller_config)
self._access = access.MemoryAccess(**access_config)
self._access_output_size = np.prod(self._access.output_size.as_list())
self._output_size = output_size
self._clip_value = clip_value or 0
self._output_size = tf.TensorShape([output_size])
self._state_size = DNCState(
access_output=self._access_output_size,
access_state=self._access.state_size,
controller_state=self._controller.state_size)
def _clip_if_enabled(self, x):
if self._clip_value > 0:
return tf.clip_by_value(x, -self._clip_value, self._clip_value)
else:
return x
def _build(self, inputs, prev_state):
"""Connects the DNC core into the graph.
Args:
inputs: Tensor input.
prev_state: A `DNCState` tuple containing the fields `access_output`,
`access_state` and `controller_state`. `access_state` is a 3-D Tensor
of shape `[batch_size, num_reads, word_size]` containing read words.
`access_state` is a tuple of the access module's state, and
`controller_state` is a tuple of controller module's state.
Returns:
A tuple `(output, next_state)` where `output` is a tensor and `next_state`
is a `DNCState` tuple containing the fields `access_output`,
`access_state`, and `controller_state`.
"""
prev_access_output = prev_state.access_output
prev_access_state = prev_state.access_state
prev_controller_state = prev_state.controller_state
batch_flatten = snt.BatchFlatten()
controller_input = tf.concat(
[batch_flatten(inputs), batch_flatten(prev_access_output)], 1)
controller_output, controller_state = self._controller(
controller_input, prev_controller_state)
controller_output = self._clip_if_enabled(controller_output)
controller_state = snt.nest.map(self._clip_if_enabled, controller_state)
access_output, access_state = self._access(controller_output,
prev_access_state)
output = tf.concat([controller_output, batch_flatten(access_output)], 1)
output = snt.Linear(
output_size=self._output_size.as_list()[0],
name='output_linear')(output)
output = self._clip_if_enabled(output)
return output, DNCState(
access_output=access_output,
access_state=access_state,
controller_state=controller_state)
def initial_state(self, batch_size, dtype=tf.float32):
return DNCState(
controller_state=self._controller.initial_state(batch_size, dtype),
access_state=self._access.initial_state(batch_size, dtype),
access_output=tf.zeros(
[batch_size] + self._access.output_size.as_list(), dtype))
@property
def state_size(self):
return self._state_size
@property
def output_size(self):
return self._output_size
How to Forecast
import sys
import warnings
if not sys.warnoptions:
warnings.simplefilter('ignore')
In [2]:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from datetime import datetime
from datetime import timedelta
from tqdm import tqdm
sns.set()
tf.compat.v1.random.set_random_seed(1234)
In [3]:
df = pd.read_csv('../dataset/GOOG-year.csv')
df.head()
Out[3]:
| Date | Open | High | Low | Close | Adj Close | Volume | |
| 0 | 2016-11-02 | 778.200012 | 781.650024 | 763.450012 | 768.700012 | 768.700012 | 1872400 |
| 1 | 2016-11-03 | 767.250000 | 769.950012 | 759.030029 | 762.130005 | 762.130005 | 1943200 |
| 2 | 2016-11-04 | 750.659973 | 770.359985 | 750.560974 | 762.020020 | 762.020020 | 2134800 |
| 3 | 2016-11-07 | 774.500000 | 785.190002 | 772.549988 | 782.520020 | 782.520020 | 1585100 |
| 4 | 2016-11-08 | 783.400024 | 795.632996 | 780.190002 | 790.510010 | 790.510010 | 1350800 |
In [4]:
minmax = MinMaxScaler().fit(df.iloc[:, 4:5].astype('float32')) # Close index
df_log = minmax.transform(df.iloc[:, 4:5].astype('float32')) # Close index
df_log = pd.DataFrame(df_log)
df_log.head()
Out[4]:
| 0 | |
| 0 | 0.112708 |
| 1 | 0.090008 |
| 2 | 0.089628 |
| 3 | 0.160459 |
| 4 | 0.188066 |
Forecast
This example is using model 1.LSTM, if you want to use another model, you need to tweak it a little bit, but I believe it is not that hard.
I want to forecast 30 days! So just change test_size to forecast t + N ahead.
Also, I want to simulate 10 times the 10 variances in forecasted patterns. Just change simulation_size.
In [5]:
simulation_size = 10
num_layers = 1
size_layer = 128
timestamp = 5
epoch = 300
dropout_rate = 0.8
test_size = 30
learning_rate = 0.01
df_train = df_log
df.shape, df_train.shape
Out[5]:
((252, 7), (252, 1))
In [6]:
class Model:
def __init__(
self,
learning_rate,
num_layers,
size,
size_layer,
output_size,
forget_bias = 0.1,
):
def lstm_cell(size_layer):
return tf.nn.rnn_cell.LSTMCell(size_layer, state_is_tuple = False)
rnn_cells = tf.nn.rnn_cell.MultiRNNCell(
[lstm_cell(size_layer) for _ in range(num_layers)],
state_is_tuple = False,
)
self.X = tf.placeholder(tf.float32, (None, None, size))
self.Y = tf.placeholder(tf.float32, (None, output_size))
drop = tf.contrib.rnn.DropoutWrapper(
rnn_cells, output_keep_prob = forget_bias
)
self.hidden_layer = tf.placeholder(
tf.float32, (None, num_layers * 2 * size_layer)
)
self.outputs, self.last_state = tf.nn.dynamic_rnn(
drop, self.X, initial_state = self.hidden_layer, dtype = tf.float32
)
self.logits = tf.layers.dense(self.outputs[-1], output_size)
self.cost = tf.reduce_mean(tf.square(self.Y - self.logits))
self.optimizer = tf.train.AdamOptimizer(learning_rate).minimize(
self.cost
)
def calculate_accuracy(real, predict):
real = np.array(real) + 1
predict = np.array(predict) + 1
percentage = 1 - np.sqrt(np.mean(np.square((real - predict) / real)))
return percentage * 100
def anchor(signal, weight):
buffer = []
last = signal[0]
for i in signal:
smoothed_val = last * weight + (1 - weight) * i
buffer.append(smoothed_val)
last = smoothed_val
return buffer
In [7]:
def forecast():
tf.reset_default_graph()
modelnn = Model(
learning_rate, num_layers, df_log.shape[1], size_layer, df_log.shape[1], dropout_rate
)
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
date_ori = pd.to_datetime(df.iloc[:, 0]).tolist()
pbar = tqdm(range(epoch), desc = 'train loop')
for i in pbar:
init_value = np.zeros((1, num_layers * 2 * size_layer))
total_loss, total_acc = [], []
for k in range(0, df_train.shape[0] - 1, timestamp):
index = min(k + timestamp, df_train.shape[0] - 1)
batch_x = np.expand_dims(
df_train.iloc[k : index, :].values, axis = 0
)
batch_y = df_train.iloc[k + 1 : index + 1, :].values
logits, last_state, _, loss = sess.run(
[modelnn.logits, modelnn.last_state, modelnn.optimizer, modelnn.cost],
feed_dict = {
modelnn.X: batch_x,
modelnn.Y: batch_y,
modelnn.hidden_layer: init_value,
},
)
init_value = last_state
total_loss.append(loss)
total_acc.append(calculate_accuracy(batch_y[:, 0], logits[:, 0]))
pbar.set_postfix(cost = np.mean(total_loss), acc = np.mean(total_acc))
future_day = test_size
output_predict = np.zeros((df_train.shape[0] + future_day, df_train.shape[1]))
output_predict[0] = df_train.iloc[0]
upper_b = (df_train.shape[0] // timestamp) * timestamp
init_value = np.zeros((1, num_layers * 2 * size_layer))
for k in range(0, (df_train.shape[0] // timestamp) * timestamp, timestamp):
out_logits, last_state = sess.run(
[modelnn.logits, modelnn.last_state],
feed_dict = {
modelnn.X: np.expand_dims(
df_train.iloc[k : k + timestamp], axis = 0
),
modelnn.hidden_layer: init_value,
},
)
init_value = last_state
output_predict[k + 1 : k + timestamp + 1] = out_logits
if upper_b != df_train.shape[0]:
out_logits, last_state = sess.run(
[modelnn.logits, modelnn.last_state],
feed_dict = {
modelnn.X: np.expand_dims(df_train.iloc[upper_b:], axis = 0),
modelnn.hidden_layer: init_value,
},
)
output_predict[upper_b + 1 : df_train.shape[0] + 1] = out_logits
future_day -= 1
date_ori.append(date_ori[-1] + timedelta(days = 1))
init_value = last_state
for i in range(future_day):
o = output_predict[-future_day - timestamp + i:-future_day + i]
out_logits, last_state = sess.run(
[modelnn.logits, modelnn.last_state],
feed_dict = {
modelnn.X: np.expand_dims(o, axis = 0),
modelnn.hidden_layer: init_value,
},
)
init_value = last_state
output_predict[-future_day + i] = out_logits[-1]
date_ori.append(date_ori[-1] + timedelta(days = 1))
output_predict = minmax.inverse_transform(output_predict)
deep_future = anchor(output_predict[:, 0], 0.4)
return deep_future
In [8]:
results = []
for i in range(simulation_size):
print('simulation %d'%(i + 1))
results.append(forecast())
WARNING: Logging before flag parsing goes to stderr.
W0818 12:00:52.795618 140214804277056 deprecation.py:323] From <ipython-input-6-d01d21f09afe>:12: LSTMCell.__init__ (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.
Instructions for updating:
This class is equivalent as tf.keras.layers.LSTMCell, and will be replaced by that in Tensorflow 2.0.
W0818 12:00:52.799092 140214804277056 rnn_cell_impl.py:893] <tensorflow.python.ops.rnn_cell_impl.LSTMCell object at 0x7f8644897400>: Using a concatenated state is slower and will soon be deprecated. Use state_is_tuple=True.
W0818 12:00:52.801252 140214804277056 deprecation.py:323] From <ipython-input-6-d01d21f09afe>:16: MultiRNNCell.__init__ (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.
Instructions for updating:
This class is equivalent as tf.keras.layers.StackedRNNCells, and will be replaced by that in Tensorflow 2.0.
simulation 1
W0818 12:00:53.121960 140214804277056 lazy_loader.py:50]
The TensorFlow contrib module will not be included in TensorFlow 2.0.
For more information, please see:
* https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
* https://github.com/tensorflow/addons
* https://github.com/tensorflow/io (for I/O related ops)
If you depend on functionality not listed there, please file an issue.
W0818 12:00:53.125179 140214804277056 deprecation.py:323] From <ipython-input-6-d01d21f09afe>:27: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.
Instructions for updating:
Please use `keras.layers.RNN(cell)`, which is equivalent to this API
W0818 12:00:53.314420 140214804277056 deprecation.py:506] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/init_ops.py:1251: calling VarianceScaling.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
W0818 12:00:53.321002 140214804277056 deprecation.py:506] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/rnn_cell_impl.py:961: calling Zeros.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
W0818 12:00:53.718872 140214804277056 deprecation.py:323] From <ipython-input-6-d01d21f09afe>:29: dense (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.dense instead.
train loop: 100%|██████████| 300/300 [01:17<00:00, 3.90it/s, acc=95.9, cost=0.00437]
W0818 12:02:12.766668 140214804277056 rnn_cell_impl.py:893] <tensorflow.python.ops.rnn_cell_impl.LSTMCell object at 0x7f85be966eb8>: Using a concatenated state is slower and will soon be deprecated. Use state_is_tuple=True.
simulation 2
train loop: 100%|██████████| 300/300 [01:18<00:00, 3.81it/s, acc=96.2, cost=0.00386]
W0818 12:03:31.524121 140214804277056 rnn_cell_impl.py:893] <tensorflow.python.ops.rnn_cell_impl.LSTMCell object at 0x7f85b4c59dd8>: Using a concatenated state is slower and will soon be deprecated. Use state_is_tuple=True.
simulation 3
train loop: 100%|██████████| 300/300 [01:17<00:00, 3.86it/s, acc=95.9, cost=0.00421]
W0818 12:04:49.292782 140214804277056 rnn_cell_impl.py:893] <tensorflow.python.ops.rnn_cell_impl.LSTMCell object at 0x7f85ac67f5f8>: Using a concatenated state is slower and will soon be deprecated. Use state_is_tuple=True.
simulation 4
train loop: 100%|██████████| 300/300 [01:17<00:00, 3.85it/s, acc=95.1, cost=0.00617]
W0818 12:06:07.690939 140214804277056 rnn_cell_impl.py:893] <tensorflow.python.ops.rnn_cell_impl.LSTMCell object at 0x7f85209545f8>: Using a concatenated state is slower and will soon be deprecated. Use state_is_tuple=True.
simulation 5
train loop: 100%|██████████| 300/300 [01:18<00:00, 3.81it/s, acc=96.8, cost=0.00293]
W0818 12:07:26.842436 140214804277056 rnn_cell_impl.py:893] <tensorflow.python.ops.rnn_cell_impl.LSTMCell object at 0x7f85089d1128>: Using a concatenated state is slower and will soon be deprecated. Use state_is_tuple=True.
simulation 6
train loop: 100%|██████████| 300/300 [01:17<00:00, 3.82it/s, acc=97.3, cost=0.00178]
W0818 12:08:45.222193 140214804277056 rnn_cell_impl.py:893] <tensorflow.python.ops.rnn_cell_impl.LSTMCell object at 0x7f85082c6160>: Using a concatenated state is slower and will soon be deprecated. Use state_is_tuple=True.
simulation 7
train loop: 100%|██████████| 300/300 [01:16<00:00, 3.94it/s, acc=97.5, cost=0.00161]
W0818 12:10:01.933482 140214804277056 rnn_cell_impl.py:893] <tensorflow.python.ops.rnn_cell_impl.LSTMCell object at 0x7f84fc7de208>: Using a concatenated state is slower and will soon be deprecated. Use state_is_tuple=True.
simulation 8
train loop: 100%|██████████| 300/300 [01:17<00:00, 3.81it/s, acc=97.5, cost=0.00156]
W0818 12:11:20.348971 140214804277056 rnn_cell_impl.py:893] <tensorflow.python.ops.rnn_cell_impl.LSTMCell object at 0x7f84fc7127b8>: Using a concatenated state is slower and will soon be deprecated. Use state_is_tuple=True.
simulation 9
train loop: 100%|██████████| 300/300 [01:18<00:00, 3.81it/s, acc=96.7, cost=0.00297]
W0818 12:12:39.812369 140214804277056 rnn_cell_impl.py:893] <tensorflow.python.ops.rnn_cell_impl.LSTMCell object at 0x7f84f6ed44a8>: Using a concatenated state is slower and will soon be deprecated. Use state_is_tuple=True.
simulation 10
train loop: 100%|██████████| 300/300 [01:17<00:00, 3.98it/s, acc=97.5, cost=0.00179]
In [10]:
date_ori = pd.to_datetime(df.iloc[:, 0]).tolist()
for i in range(test_size):
date_ori.append(date_ori[-1] + timedelta(days = 1))
date_ori = pd.Series(date_ori).dt.strftime(date_format = '%Y-%m-%d').tolist()
date_ori[-5:]
Out[10]:
['2017-11-27', '2017-11-28', '2017-11-29', '2017-11-30', '2017-12-01']
Sanity check
Some of our models might not have stable gradients, so the forecasted trends might hang weird. You can use many methods to filter out unstable models.
This method is very simple,
If one of the elements in the forecasted trend is lower than min(original trend).
If one of the elements in the forecasted trend is bigger than the max(original trend) * 2.
If both are true, reject that trend.
In [13]:
accepted_results = []
for r in results:
if (np.array(r[-test_size:]) < np.min(df['Close'])).sum() == 0 and \
(np.array(r[-test_size:]) > np.max(df['Close']) * 2).sum() == 0:
accepted_results.append(r)
len(accepted_results)
Out[13]:
6
In [14]:
accuracies = [calculate_accuracy(df['Close'].values, r[:-test_size]) for r in accepted_results]
plt.figure(figsize = (15, 5))
for no, r in enumerate(accepted_results):
plt.plot(r, label = 'forecast %d'%(no + 1))
plt.plot(df['Close'], label = 'true trend', c = 'black')
plt.legend()
plt.title('average accuracy: %.4f'%(np.mean(accuracies)))
x_range_future = np.arange(len(results[0]))
plt.xticks(x_range_future[::30], date_ori[::30])
plt.show()
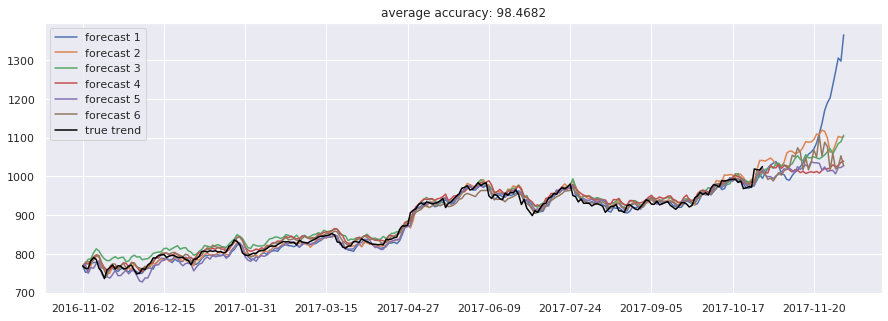
Sentiment Consensus
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from datetime import datetime
from datetime import timedelta
sns.set()
tf.compat.v1.random.set_random_seed(1234)
In [2]:
df = pd.read_csv('../dataset/BTC-sentiment.csv')
df.head()
Out[2]:
| Timestamp | close | positive | negative | |
| 0 | 2019-08-09T23:00:00 | 11860.074544 | 0.672896 | 0.327104 |
| 1 | 2019-08-09T23:20:00 | 11872.025879 | 0.595100 | 0.404900 |
| 2 | 2019-08-09T23:40:00 | 11880.504557 | 0.596702 | 0.403298 |
| 3 | 2019-08-10T00:00:00 | 11918.873481 | 0.577972 | 0.422028 |
| 4 | 2019-08-10T00:20:00 | 11937.581272 | 0.585342 | 0.414658 |
Here's how we gather the data, provided by Bitcurate: bitcurate.com
Since I don't have sentiment data related to the stock market, I will use cryptocurrency data, BTC/USDT from Binance.
closed data came from CCXT, https://github.com/ccxt/ccxt, an open-source cryptocurrency aggregator.
We gather from streaming Twitter, crawling hardcoded cryptocurrency telegram groups and Reddit. We store it in Elasticsearch as a single index. We trained 1/4 layers of REST MULTILANGUAGE (200MB-ish, originally 700MB-ish) released by Google on the most-possible-found sentiment data on the internet, leveraging sentiment in multi-languages, eg, English, Korean, and Japan. It is very hard to find negative sentiment related to bitcoin / btc in large volume.
How do we request using elasticsearch-dsl.https://elasticsearch-dsl..,
# from index name
s = s.filter(
'query_string',
default_field = 'text',
query = 'bitcoin OR btc',
)
We only do text queries that only contain bitcoin or BTC.
Consensus introduction
We have 2 questions here when talking about consensus, what happened,
to the future price if we assume future sentiment is positive, near 1.0? Eg, suddenly China wants to adopt cryptocurrency and that can cause huge requested volumes.
to the future price if we assume future sentiment will be negative, near 1.0. Eg, suddenly hackers broke Binance or any exchanges, or any news that was caused wrecked by negative sentiment.
In [3]:
from mpl_toolkits.axes_grid1 import host_subplot
import mpl_toolkits.axisartist as AA
close = df['close'].tolist()
positive = df['positive'].tolist()
negative = df['negative'].tolist()
timestamp = df['timestamp'].tolist()
plt.figure(figsize = (17, 5))
host = host_subplot(111)
plt.subplots_adjust(right = 0.75, top = 0.8)
par1 = host.twinx()
par2 = host.twinx()
par2.spines['right'].set_position(('axes', 1.1))
par2.spines['bottom'].set_position(('axes', 0.9))
host.set_xlabel('timestamp')
host.set_ylabel('BTC/USDT')
par1.set_ylabel('positive')
par2.set_ylabel('negative')
host.plot(close, label = 'BTC/USDT')
par1.plot(positive, label = 'positive')
par2.plot(negative, label = 'negative')
host.legend()
plt.xticks(
np.arange(len(timestamp))[::30], timestamp[::30], rotation = '45', ha = 'right'
)
plt.legend()
plt.show()
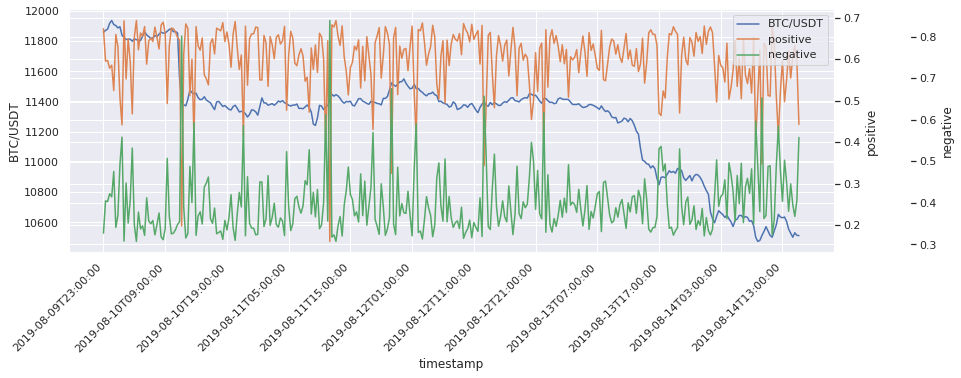
minmax = MinMaxScaler().fit(df.iloc[:, 1:2].astype('float32'))
df_log = minmax.transform(df.iloc[:, 1:2].astype('float32'))
df_log = pd.DataFrame(df_log)
df_log[1] = df['positive']
df_log[2] = df['negative']
df_log.head()
Out[4]:
| 0 | 1 | 2 | |
| 0 | 0.947020 | 0.672896 | 0.327104 |
| 1 | 0.955190 | 0.595100 | 0.404900 |
| 2 | 0.960986 | 0.596702 | 0.403298 |
| 3 | 0.987212 | 0.577972 | 0.422028 |
| 4 | 1.000000 | 0.585342 | 0.414658 |
Model definition
This example is using model 17.CNN-seq2seq, if you want to use another model, you need to tweak it a little bit, but I believe it is not that hard.
In [5]:
num_layers = 1
size_layer = 128
epoch = 200
dropout_rate = 0.75
test_size = 3 * 10 # timestamp every 20 minutes, and I want to test on last 12 hours
learning_rate = 1e-3
timestamp = test_size
df_train = df_log.iloc[:-test_size]
df_test = df_log.iloc[-test_size:]
df.shape, df_train.shape, df_test.shape
Out[5]:
((339, 4), (309, 3), (30, 3))
In [6]:
def encoder_block(inp, n_hidden, filter_size):
inp = tf.expand_dims(inp, 2)
inp = tf.pad(
inp,
[
[0, 0],
[(filter_size[0] - 1) // 2, (filter_size[0] - 1) // 2],
[0, 0],
[0, 0],
],
)
conv = tf.layers.conv2d(
inp, n_hidden, filter_size, padding = 'VALID', activation = None
)
conv = tf.squeeze(conv, 2)
return conv
def decoder_block(inp, n_hidden, filter_size):
inp = tf.expand_dims(inp, 2)
inp = tf.pad(inp, [[0, 0], [filter_size[0] - 1, 0], [0, 0], [0, 0]])
conv = tf.layers.conv2d(
inp, n_hidden, filter_size, padding = 'VALID', activation = None
)
conv = tf.squeeze(conv, 2)
return conv
def glu(x):
return tf.multiply(
x[:, :, : tf.shape(x)[2] // 2],
tf.sigmoid(x[:, :, tf.shape(x)[2] // 2 :]),
)
def layer(inp, conv_block, kernel_width, n_hidden, residual = None):
z = conv_block(inp, n_hidden, (kernel_width, 1))
return glu(z) + (residual if residual is not None else 0)
class Model:
def __init__(
self,
learning_rate,
num_layers,
size,
size_layer,
output_size,
kernel_size = 3,
n_attn_heads = 16,
dropout = 0.9,
):
self.X = tf.placeholder(tf.float32, (None, None, size))
self.Y = tf.placeholder(tf.float32, (None, output_size))
encoder_embedded = tf.layers.dense(self.X, size_layer)
e = tf.identity(encoder_embedded)
for i in range(num_layers):
z = layer(
encoder_embedded,
encoder_block,
kernel_size,
size_layer * 2,
encoder_embedded,
)
z = tf.nn.dropout(z, keep_prob = dropout)
encoder_embedded = z
encoder_output, output_memory = z, z + e
g = tf.identity(encoder_embedded)
for i in range(num_layers):
attn_res = h = layer(
encoder_embedded,
decoder_block,
kernel_size,
size_layer * 2,
residual = tf.zeros_like(encoder_embedded),
)
C = []
for j in range(n_attn_heads):
h_ = tf.layers.dense(h, size_layer // n_attn_heads)
g_ = tf.layers.dense(g, size_layer // n_attn_heads)
zu_ = tf.layers.dense(
encoder_output, size_layer // n_attn_heads
)
ze_ = tf.layers.dense(output_memory, size_layer // n_attn_heads)
d = tf.layers.dense(h_, size_layer // n_attn_heads) + g_
dz = tf.matmul(d, tf.transpose(zu_, [0, 2, 1]))
a = tf.nn.softmax(dz)
c_ = tf.matmul(a, ze_)
C.append(c_)
c = tf.concat(C, 2)
h = tf.layers.dense(attn_res + c, size_layer)
h = tf.nn.dropout(h, keep_prob = dropout)
encoder_embedded = h
encoder_embedded = tf.sigmoid(encoder_embedded[-1])
self.logits = tf.layers.dense(encoder_embedded, output_size)
self.cost = tf.reduce_mean(tf.square(self.Y - self.logits))
self.optimizer = tf.train.AdamOptimizer(learning_rate).minimize(
self.cost
)
def calculate_accuracy(real, predict):
real = np.array(real) + 1
predict = np.array(predict) + 1
percentage = 1 - np.sqrt(np.mean(np.square((real - predict) / real)))
return percentage * 100
def anchor(signal, weight):
buffer = []
last = signal[0]
for i in signal:
smoothed_val = last * weight + (1 - weight) * i
buffer.append(smoothed_val)
last = smoothed_val
return buffer
In [7]:
tf.reset_default_graph()
modelnn = Model(
learning_rate, num_layers, df_log.shape[1], size_layer, df_log.shape[1],
dropout = dropout_rate
)
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
WARNING: Logging before flag parsing goes to stderr.
W0818 16:34:24.824237 140007582447424 deprecation.py:323] From <ipython-input-6-6c0655f4345e>:55: dense (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.dense instead.
W0818 16:34:24.831443 140007582447424 deprecation.py:506] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/init_ops.py:1251: calling VarianceScaling.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
W0818 16:34:25.094202 140007582447424 deprecation.py:323] From <ipython-input-6-6c0655f4345e>:13: conv2d (from tensorflow.python.layers.convolutional) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.keras.layers.Conv2D` instead.
W0818 16:34:25.236837 140007582447424 deprecation.py:506] From <ipython-input-6-6c0655f4345e>:66: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
In [8]:
from tqdm import tqdm
pbar = tqdm(range(epoch), desc = 'train loop')
for i in pbar:
init_value = np.zeros((1, num_layers * 2 * size_layer))
total_loss, total_acc = [], []
for k in range(0, df_train.shape[0] - 1, timestamp):
index = min(k + timestamp, df_train.shape[0] - 1)
batch_x = np.expand_dims(
df_train.iloc[k : index, :].values, axis = 0
)
batch_y = df_train.iloc[k + 1 : index + 1, :].values
logits, _, loss = sess.run(
[modelnn.logits, modelnn.optimizer, modelnn.cost],
feed_dict = {modelnn.X: batch_x, modelnn.Y: batch_y},
)
total_loss.append(loss)
total_acc.append(calculate_accuracy(batch_y[:, 0], logits[:, 0]))
pbar.set_postfix(cost = np.mean(total_loss), acc = np.mean(total_acc))
train loop: 100%|██████████| 200/200 [00:40<00:00, 5.17it/s, acc=98, cost=0.000637]
In [9]:
future_day = test_size
output_predict = np.zeros((df_train.shape[0] + future_day, df_train.shape[1]))
output_predict[0] = df_train.iloc[0]
upper_b = (df_train.shape[0] // timestamp) * timestamp
for k in range(0, (df_train.shape[0] // timestamp) * timestamp, timestamp):
out_logits = sess.run(
modelnn.logits,
feed_dict = {
modelnn.X: np.expand_dims(
df_train.iloc[k : k + timestamp], axis = 0
)
},
)
output_predict[k + 1 : k + timestamp + 1] = out_logits
if upper_b != df_train.shape[0]:
out_logits = sess.run(
modelnn.logits,
feed_dict = {
modelnn.X: np.expand_dims(df_train.iloc[upper_b:], axis = 0)
},
)
output_predict[upper_b + 1 : df_train.shape[0] + 1] = out_logits
future_day -= 1
In [10]:
output_predict_negative = output_predict.copy()
output_predict_positive = output_predict.copy()
In [11]:
for i in range(future_day):
o = output_predict[-future_day - timestamp + i:-future_day + i].copy()
o = np.expand_dims(o, axis = 0)
o_negative = output_predict_negative[-future_day - timestamp + i:-future_day + i].copy()
o_negative = np.expand_dims(o_negative, axis = 0)
o_negative[:, :, 1] = 0.0
o_negative[:, :, 2] = 1.0
o_positive = output_predict_positive[-future_day - timestamp + i:-future_day + i].copy()
o_positive = np.expand_dims(o_positive, axis = 0)
o_positive[:, :, 1] = 1.0
o_positive[:, :, 2] = 0.0
# original without any consensus
out_logits = sess.run(
modelnn.logits,
feed_dict = {
modelnn.X: o
},
)
output_predict[-future_day + i] = out_logits[-1]
# negative consensus
out_logits = sess.run(
modelnn.logits,
feed_dict = {
modelnn.X: o_negative
},
)
output_predict_negative[-future_day + i] = out_logits[-1]
# positive consensus
out_logits = sess.run(
modelnn.logits,
feed_dict = {
modelnn.X: o_positive
},
)
output_predict_positive[-future_day + i] = out_logits[-1]
In [12]:
output_predict_original = minmax.inverse_transform(output_predict[:,:1])
output_predict_negative = minmax.inverse_transform(output_predict_negative[:,:1])
output_predict_positive = minmax.inverse_transform(output_predict_positive[:,:1])
In [19]:
deep_future = anchor(output_predict_original[:, 0], 0.7)
deep_future_negative = anchor(output_predict_negative[:, 0], 0.7)
deep_future_positive = anchor(output_predict_positive[:, 0], 0.7)
In [14]:
df.shape, len(deep_future_negative)
Out[14]:
((339, 4), 339)
In [15]:
df_train = minmax.inverse_transform(df_train)
df_test = minmax.inverse_transform(df_test)
In [20]:
timestamp = df['timestamp'].tolist()
pad_test = np.pad(df_test[:,0], (df_train.shape[0], 0), 'constant', constant_values=np.nan)
plt.figure(figsize = (15, 5))
plt.plot(pad_test, label = 'test trend', c = 'blue')
plt.plot(df_train[:,0], label = 'train trend', c = 'black')
plt.plot(deep_future, label = 'forecast without consensus')
plt.plot(deep_future_negative, label = 'forecast with negative consensus', c = 'red')
plt.plot(deep_future_positive, label = 'forecast with positive consensus', c = 'green')
plt.legend()
plt.xticks(
np.arange(len(timestamp))[::30], timestamp[::30], rotation = '45', ha = 'right'
)
plt.show()
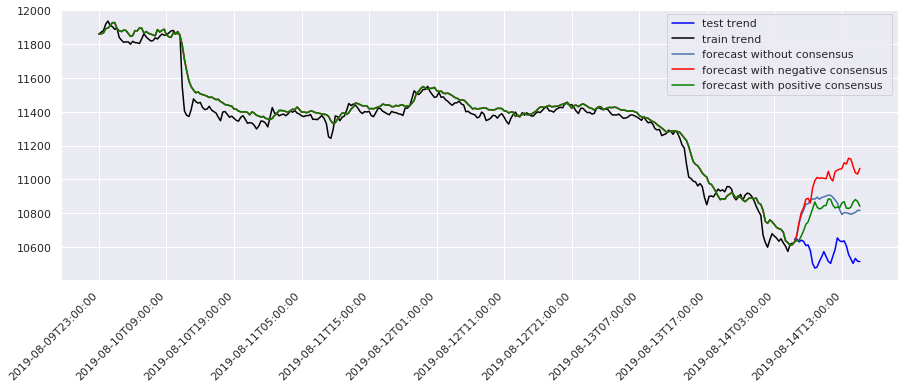
What we can observe
The model learns that if positive and negative sentiments increase, both will increase the price. That is why, using positive consensus or negative consensus caused prices to go up.
Price volatility is higher if negative sentiment is higher, but still positive volatility.
The momentum of price is higher if negative sentiment is higher, but still positive momentum.
Utility
# Copyright 2017 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""DNC util ops and modules."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np
import tensorflow as tf
def batch_invert_permutation(permutations):
"""Returns batched `tf.invert_permutation` for every row in `permutations`."""
with tf.name_scope('batch_invert_permutation', values=[permutations]):
unpacked = tf.unstack(permutations)
inverses = [tf.invert_permutation(permutation) for permutation in unpacked]
return tf.stack(inverses)
def batch_gather(values, indices):
"""Returns batched `tf.gather` for every row in the input."""
with tf.name_scope('batch_gather', values=[values, indices]):
unpacked = zip(tf.unstack(values), tf.unstack(indices))
result = [tf.gather(value, index) for value, index in unpacked]
return tf.stack(result)
def one_hot(length, index):
"""Return an nd array of given `length` filled with 0s and a 1 at `index`."""
result = np.zeros(length)
result[index] = 1
return result